02:00
Tidying data 🥞
Lecture 7
Dr. Benjamin Soltoff
Cornell University
INFO 2950 - Spring 2024
February 13, 2024
Announcements


Regrade requests
- Submit starting at noon the day after the assignment grade is published
- Due within one week of the assignment grade being published
- Regrade requests are for if you believe a mistake was made in grading your submission
- Be specific and polite in your request. We all make mistakes. If we made a mistake grading your submission, we want to correct it.
Common questions at this point
What is the difference between rendering and saving a document?
- Saving a Quarto file saves the changes in the source
.qmdfile but are not reflected in your output HTML or PDF file - When you render the document, the output is also updated to reflect those changes
- When you click “render” RStudio automatically first saves your Quarto file, then renders it
- Render early and often
- Save changes
- Identifies any errors early
- Saving a Quarto file saves the changes in the source
What does it mean to commit and push something?
- Commit stores a snapshot of the files in your local repository (i.e. the files save on the university server)
- Push gets those changes to the remote repository (i.e. your repository on GitHub)
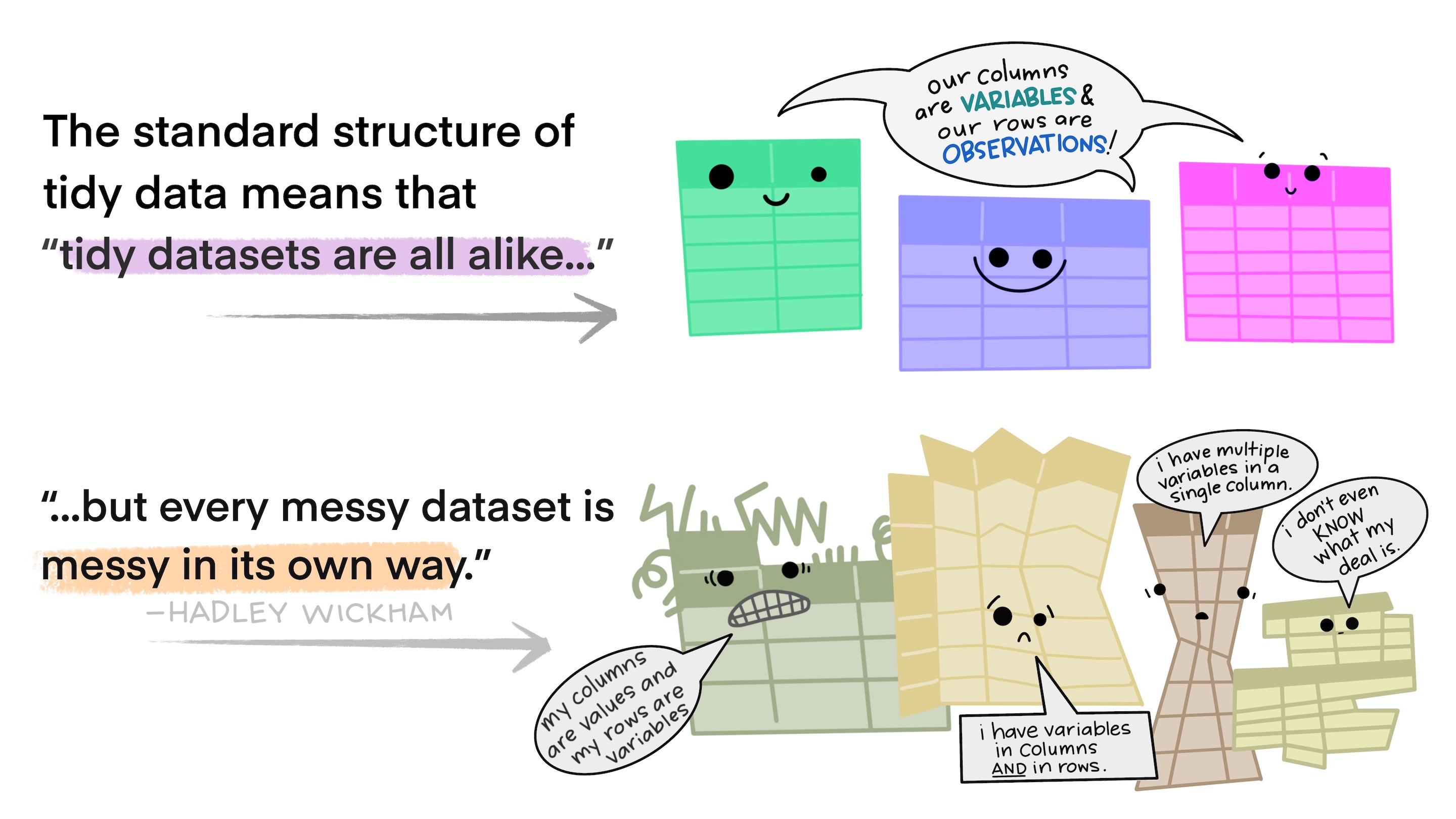
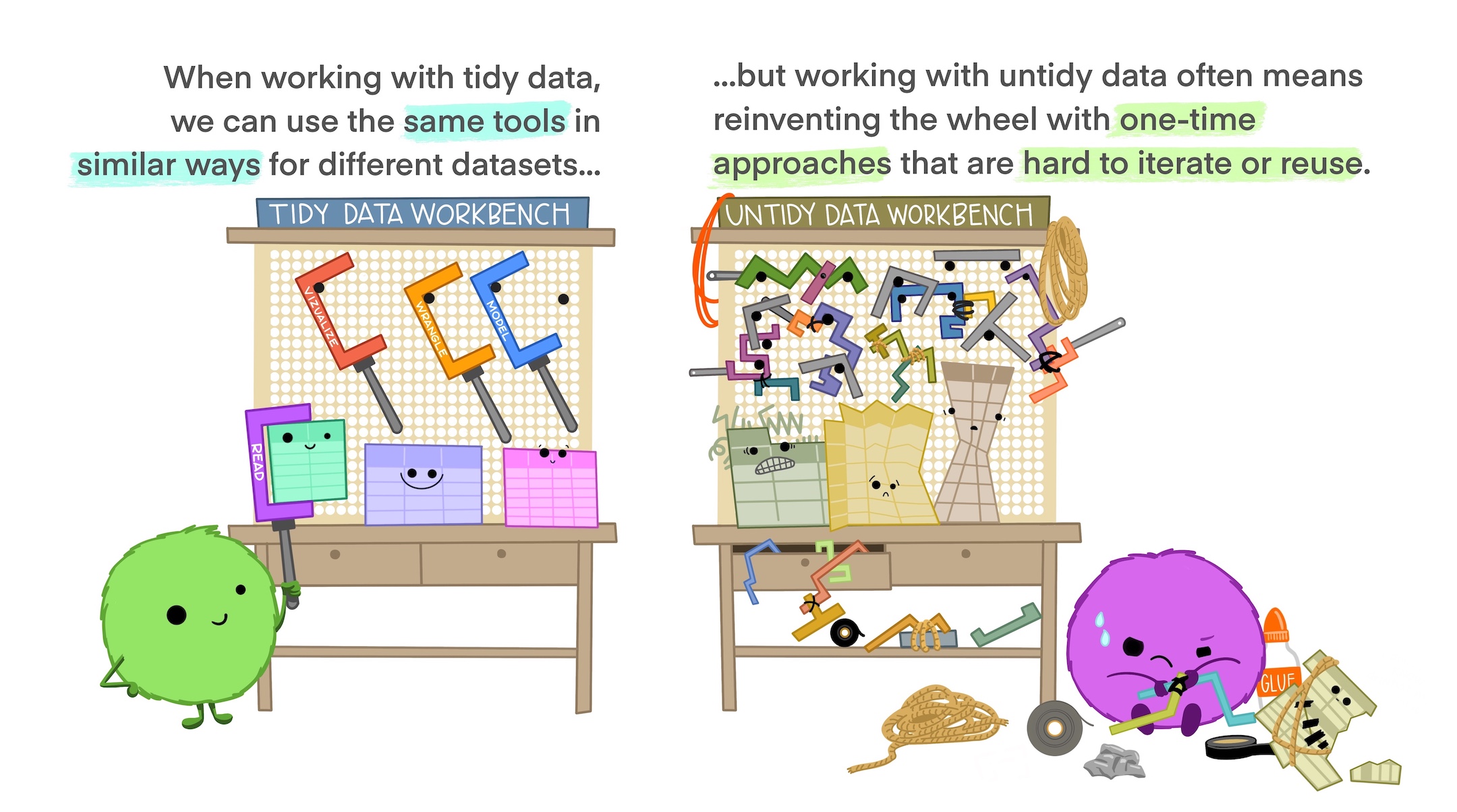
Tidying datasets
What makes a dataset “tidy”?



Application exercise
ae-05
- Go to the course GitHub org and find your
ae-05(repo name will be suffixed with your GitHub name). - Clone the repo in RStudio Workbench, open the Quarto document in the repo, and follow along and complete the exercises.
- Render, commit, and push your edits by the AE deadline – end of tomorrow.
Recap of AE
- Data sets should not be labeled as wide or long but they can be made wider or longer for a certain analysis that requires a certain format
- When pivoting longer, variable names that turn into values are characters by default. If you need them to be in another format, you need to explicitly make that transformation, which you can do so within the
pivot_longer()function. - You can tweak a plot forever, but at some point the tweaks are likely not very productive. However, you should always be critical of defaults (however pretty they might be) and see if you can improve the plot to better portray your data / results / what you want to communicate.
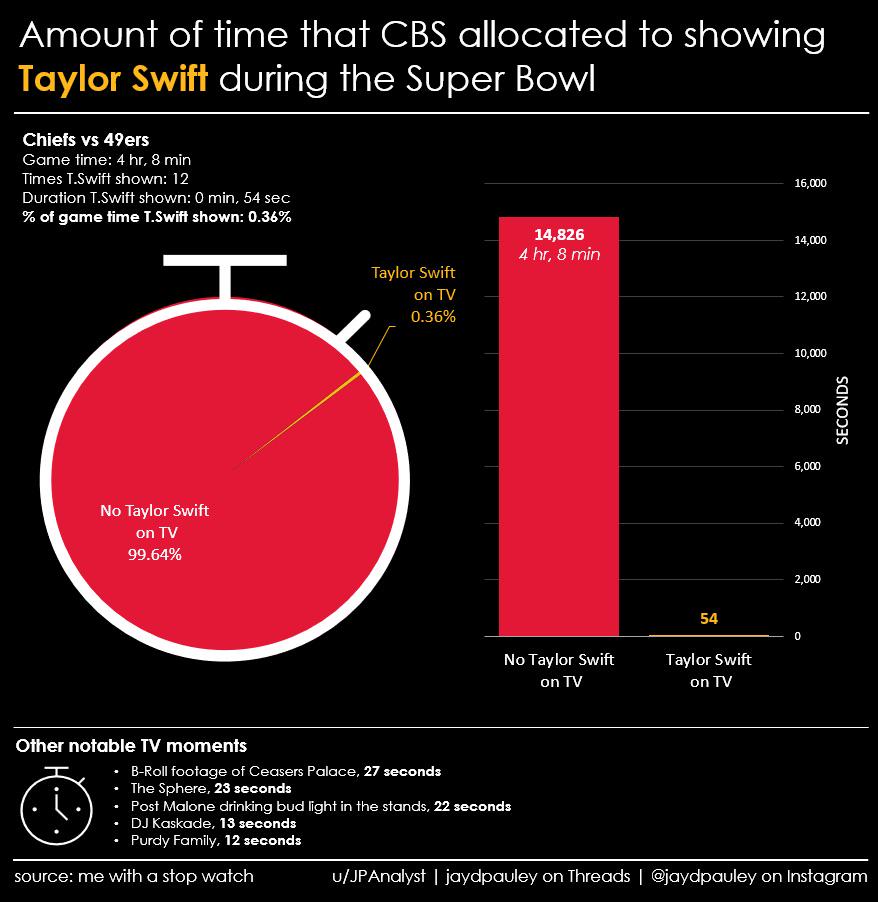
Tortured Visualizations Department