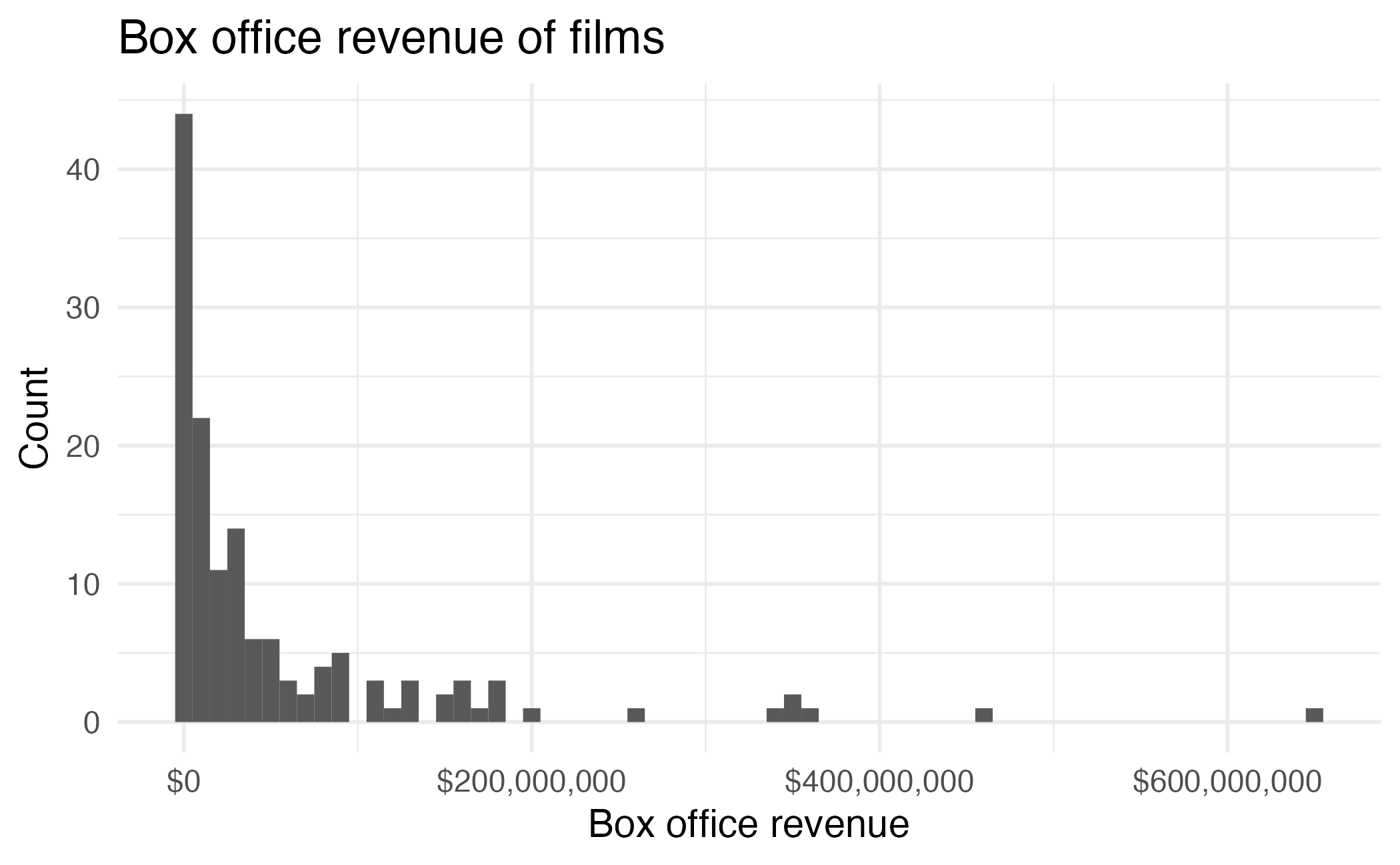
# A tibble: 146 × 5
film audience critics genre box_office
<chr> <dbl> <dbl> <chr> <dbl>
1 Avengers: Age of Ultron 86 74 Action 459005868
2 Cinderella 80 85 Adventure 201151353
3 Ant-Man 90 80 Action 180202163
4 Do You Believe? 84 18 Drama 12985600
5 Hot Tub Time Machine 2 28 14 Comedy 12314651
6 The Water Diviner 62 63 Drama 4196641
7 Irrational Man 53 42 Comedy 4030360
8 Top Five 64 86 Comedy 25317471
9 Shaun the Sheep Movie 82 99 Animation 19375982
10 Love & Mercy 87 89 Biography 12551031
# ℹ 136 more rows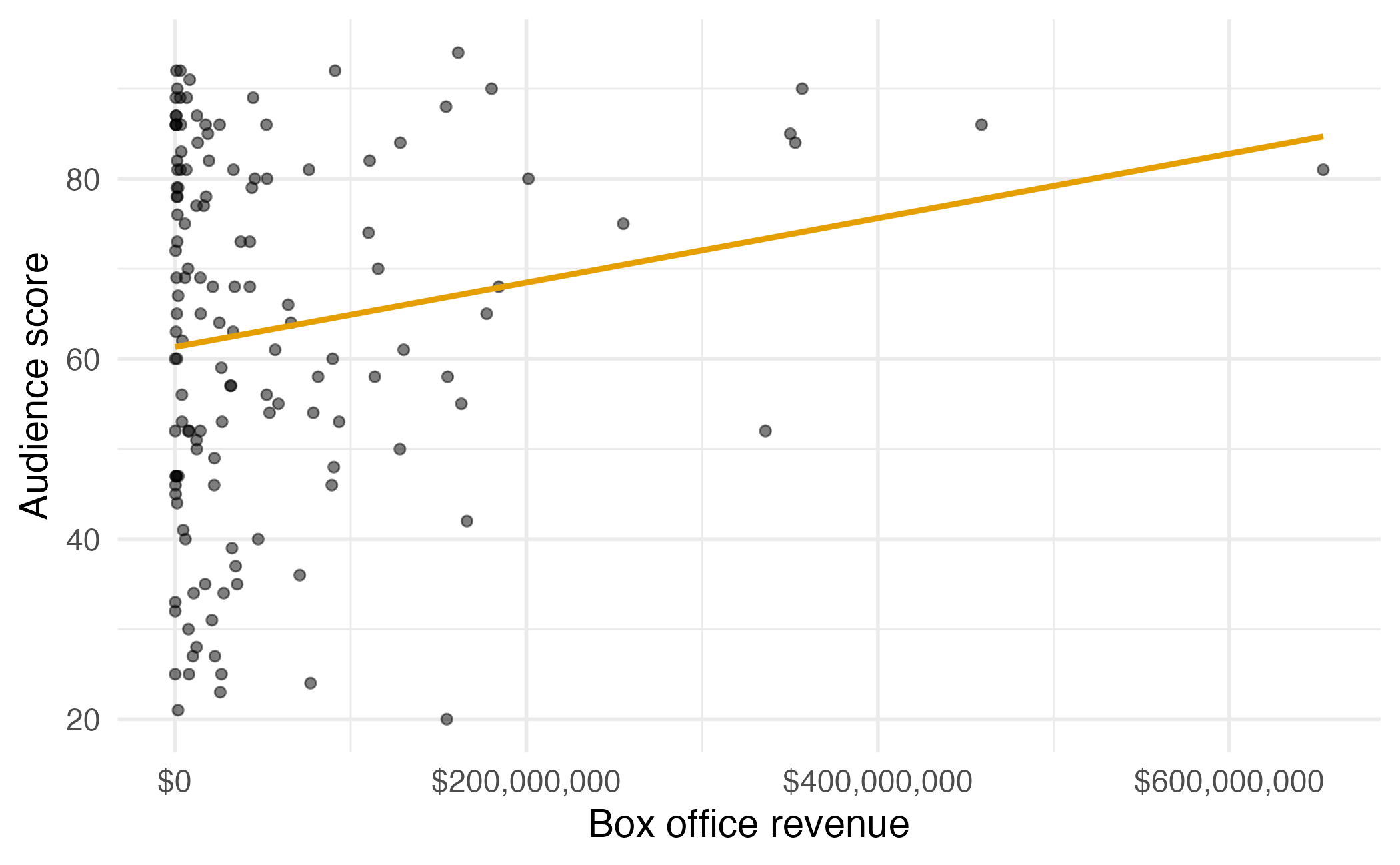
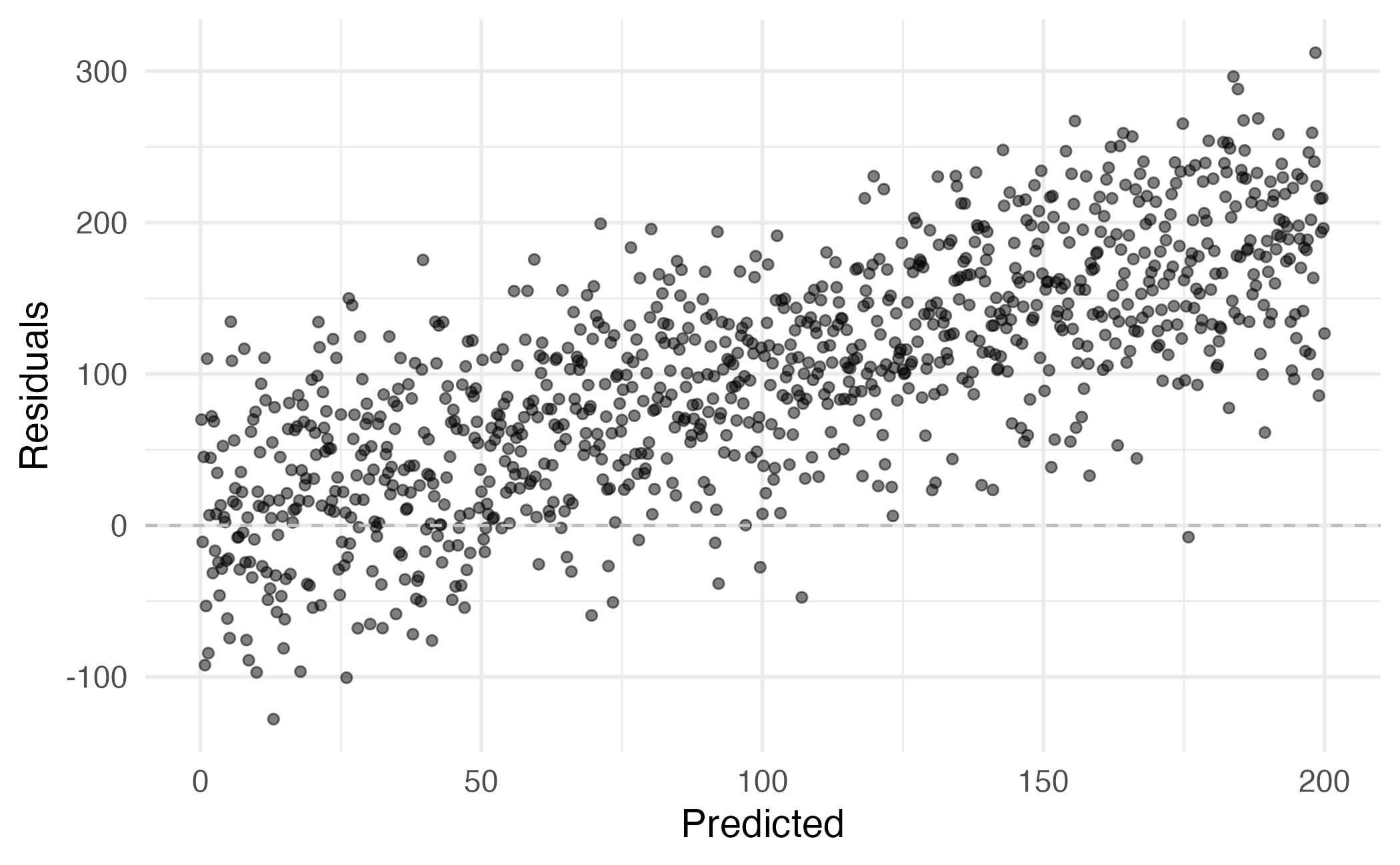
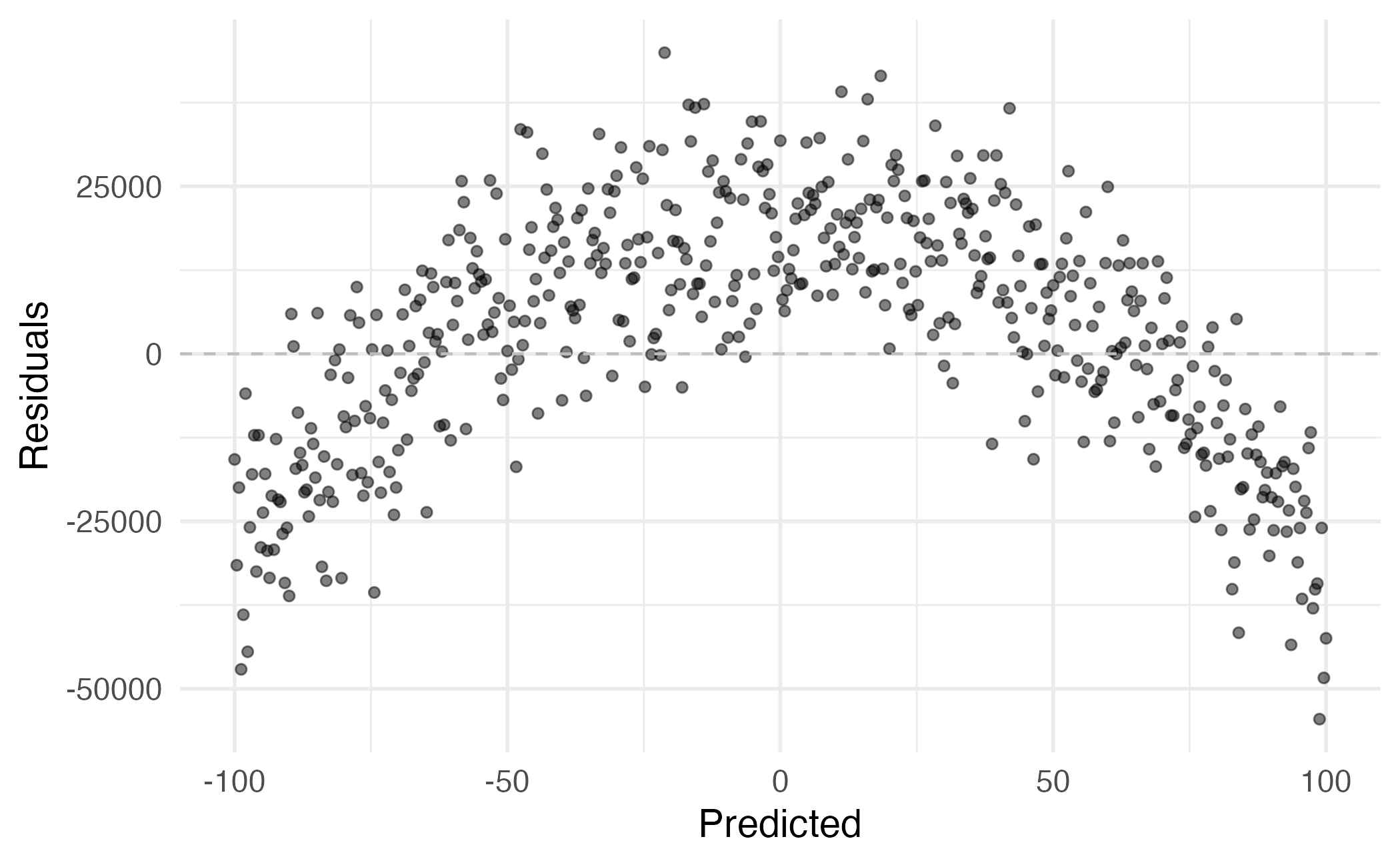
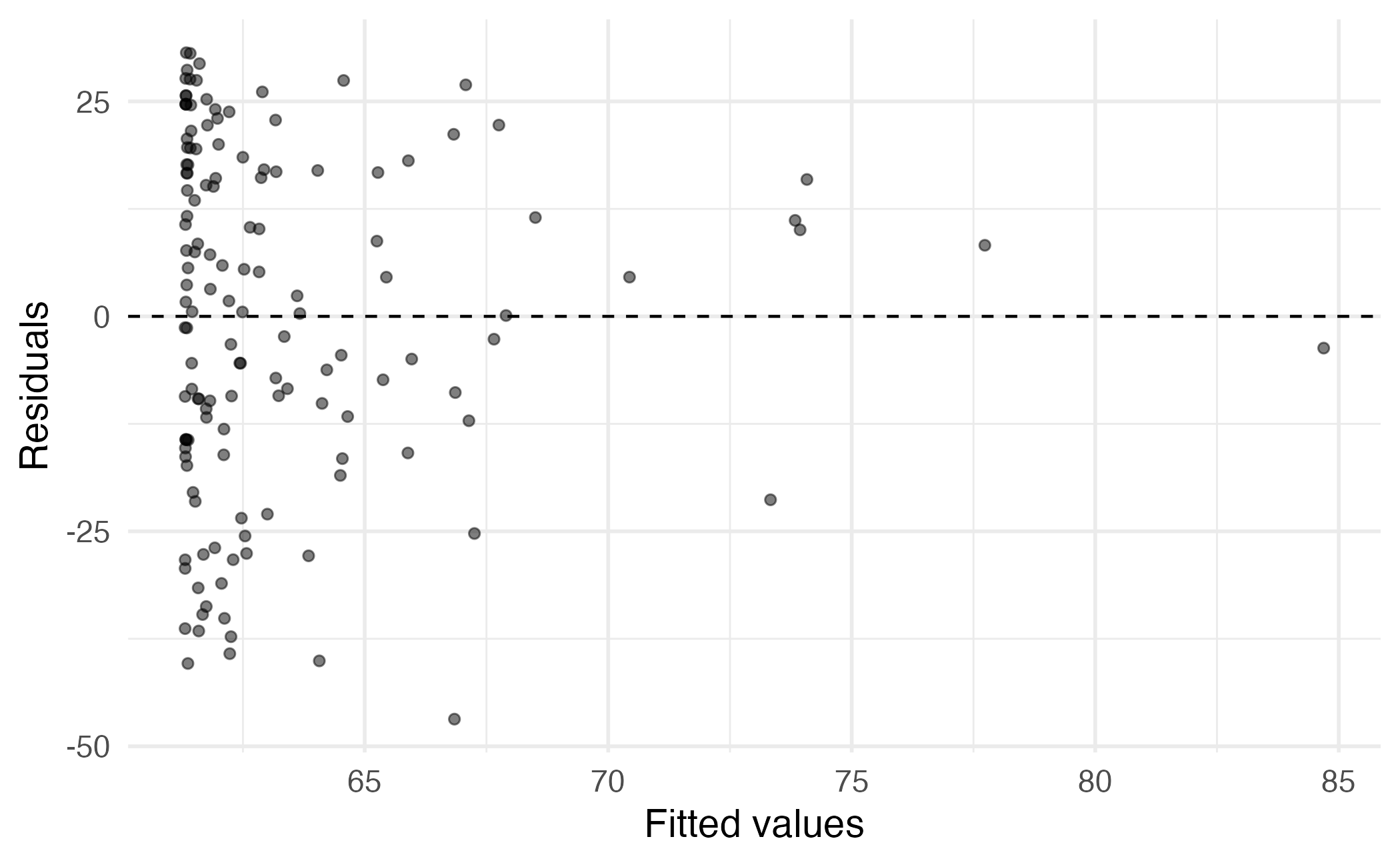
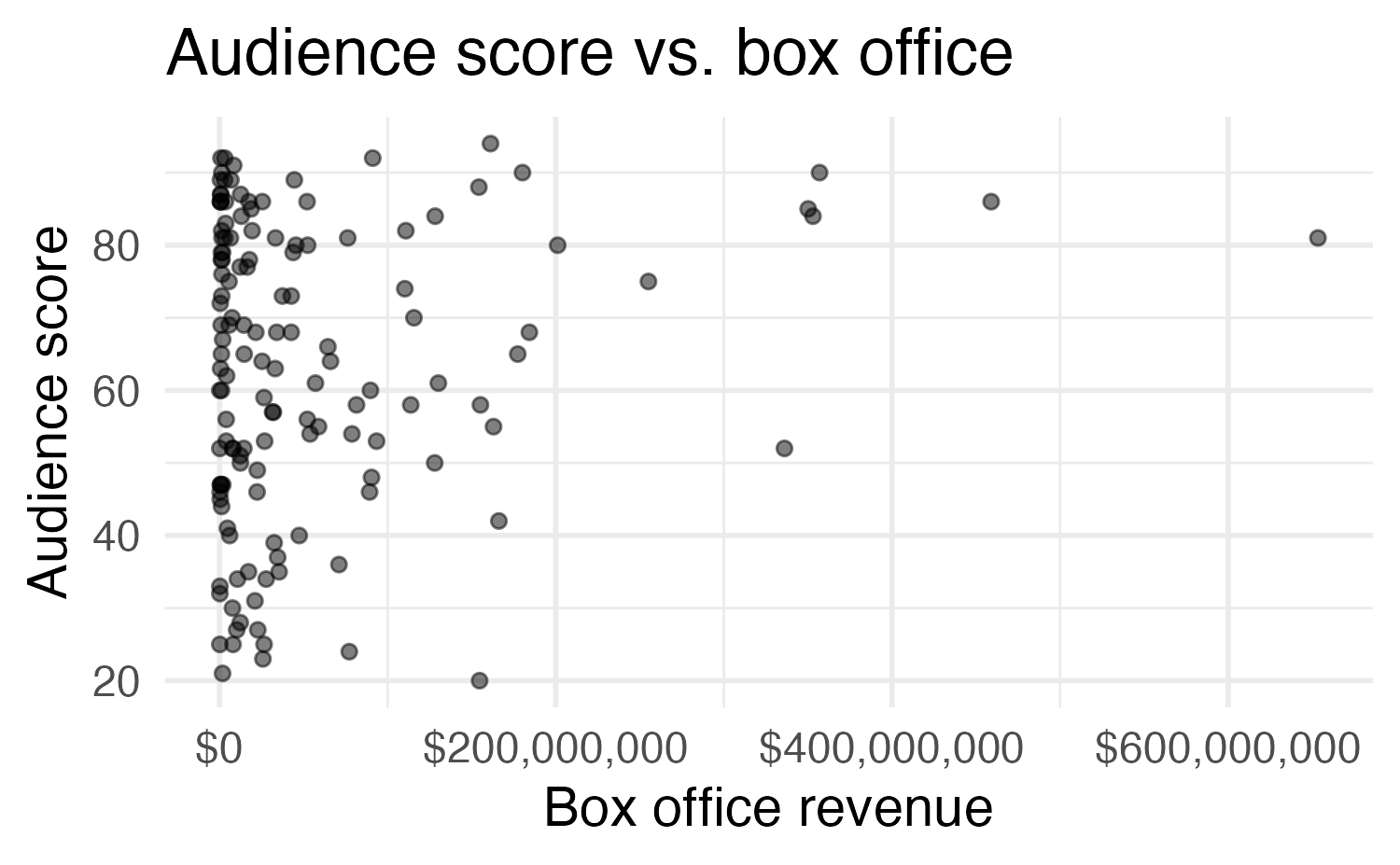
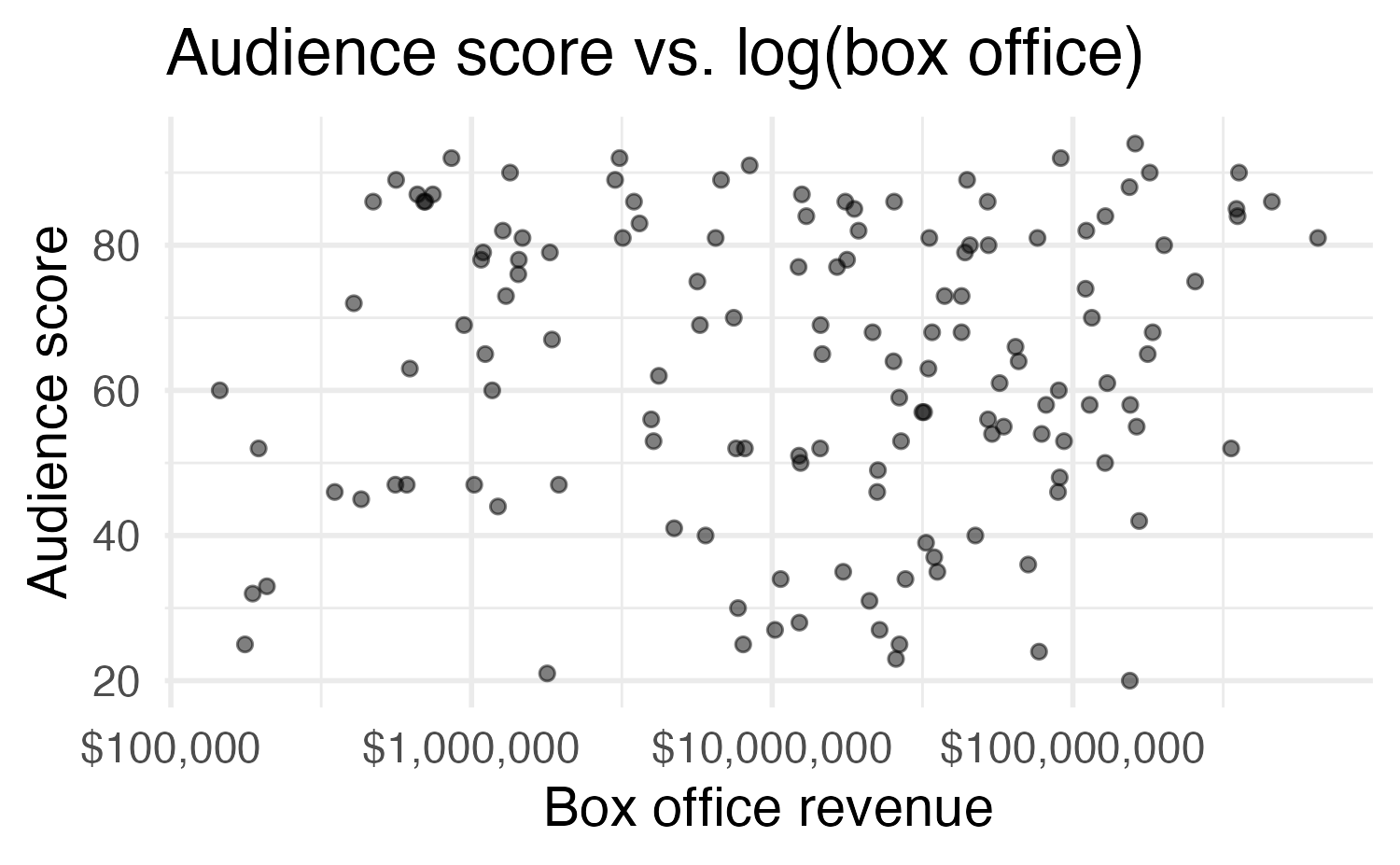
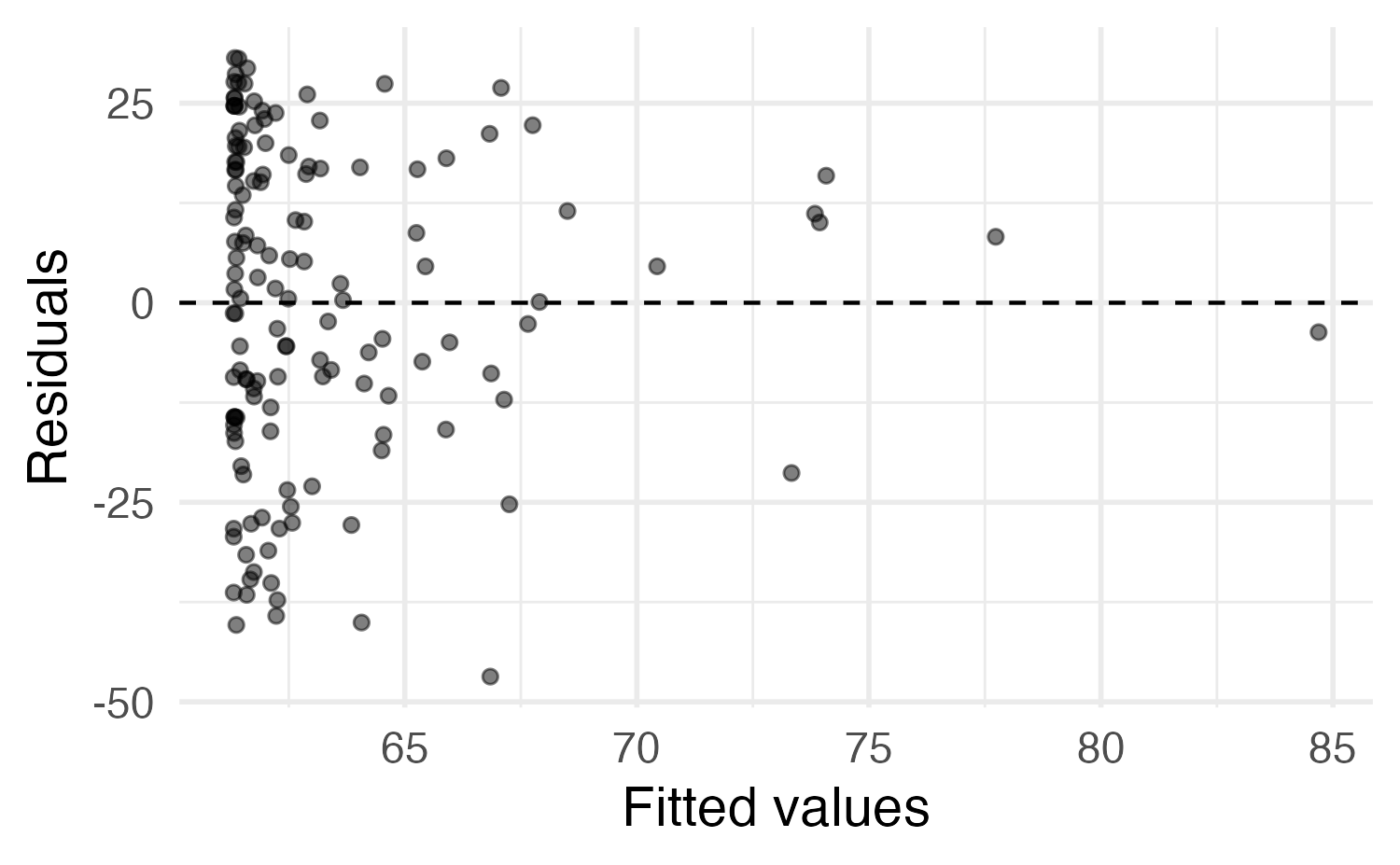
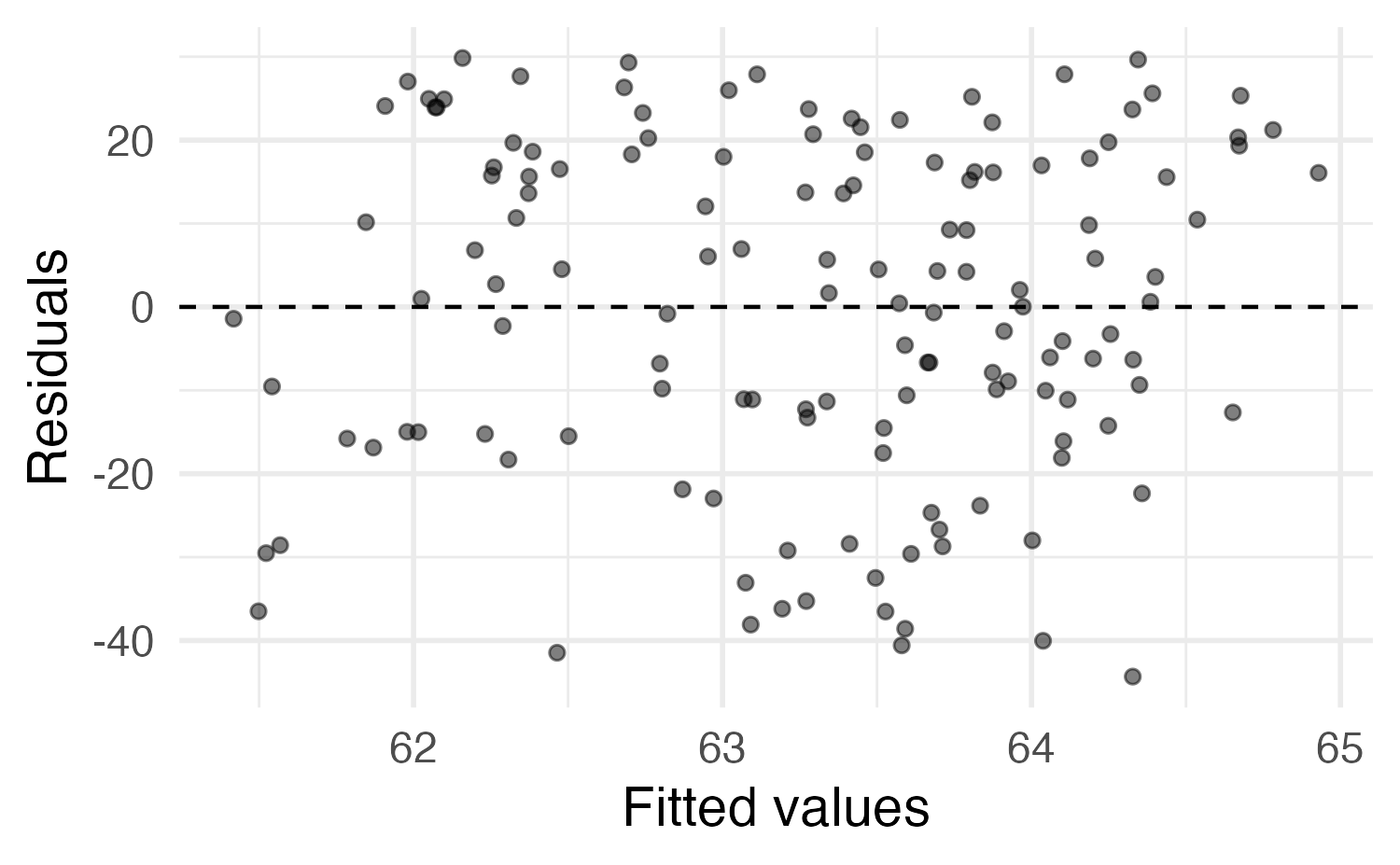

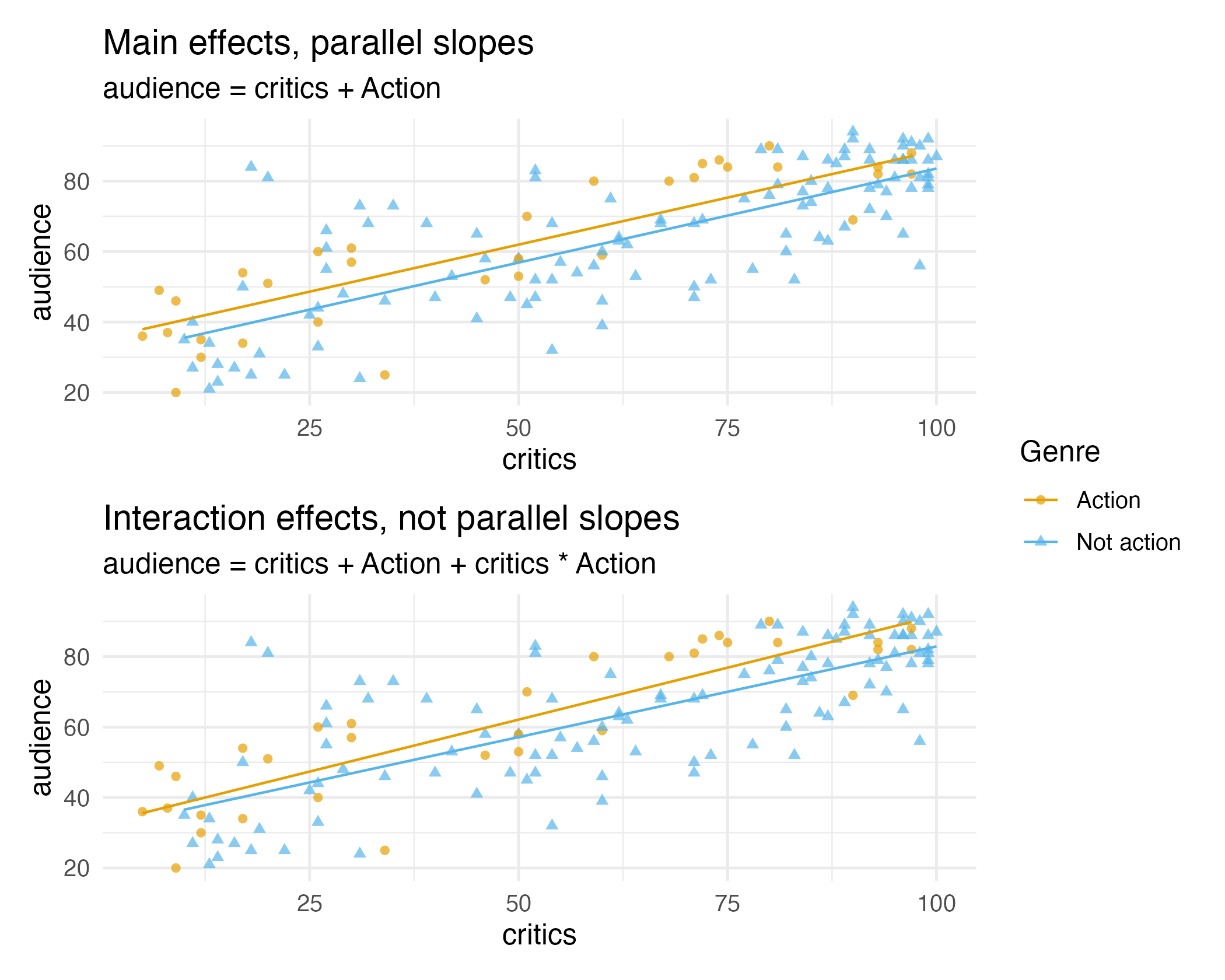
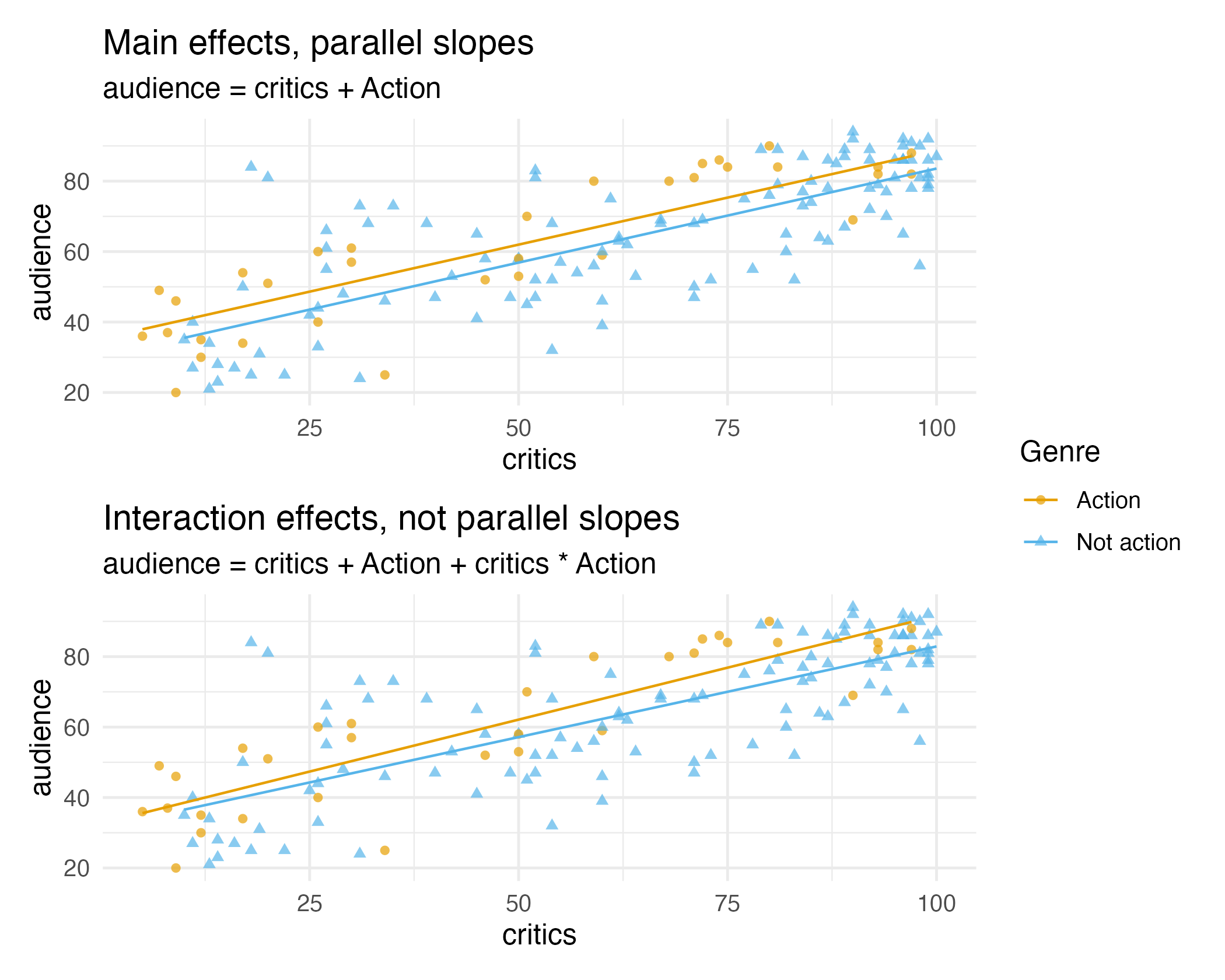
Main vs. interaction effects
Suppose we want to predict audience ratings based on critics’ ratings and whether or not it is an Action film. Do you think a model with main effects or interaction effects is more appropriate?
Hint: Main effects would mean the rate at which audience ratings change as critics’ ratings increase would be the same for Action and non-Action films, and interaction effects would mean the rate at which audience ratings change as critics’ ratings increase would be different for Action and non-Action films.