Rows: 4,449
Columns: 7
$ ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…
$ cong <dbl> 107, 107, 107, 107, 107, 107, 107, 107, 107, 107, 107, 107, 1…
$ billnum <dbl> 4499, 4500, 4501, 4502, 4503, 4504, 4505, 4506, 4507, 4508, 4…
$ h_or_sen <chr> "HR", "HR", "HR", "HR", "HR", "HR", "HR", "HR", "HR", "HR", "…
$ major <dbl> 18, 18, 18, 18, 5, 21, 15, 18, 18, 18, 18, 16, 18, 12, 2, 3, …
$ text <chr> "To suspend temporarily the duty on Fast Magenta 2 Stage.", "…
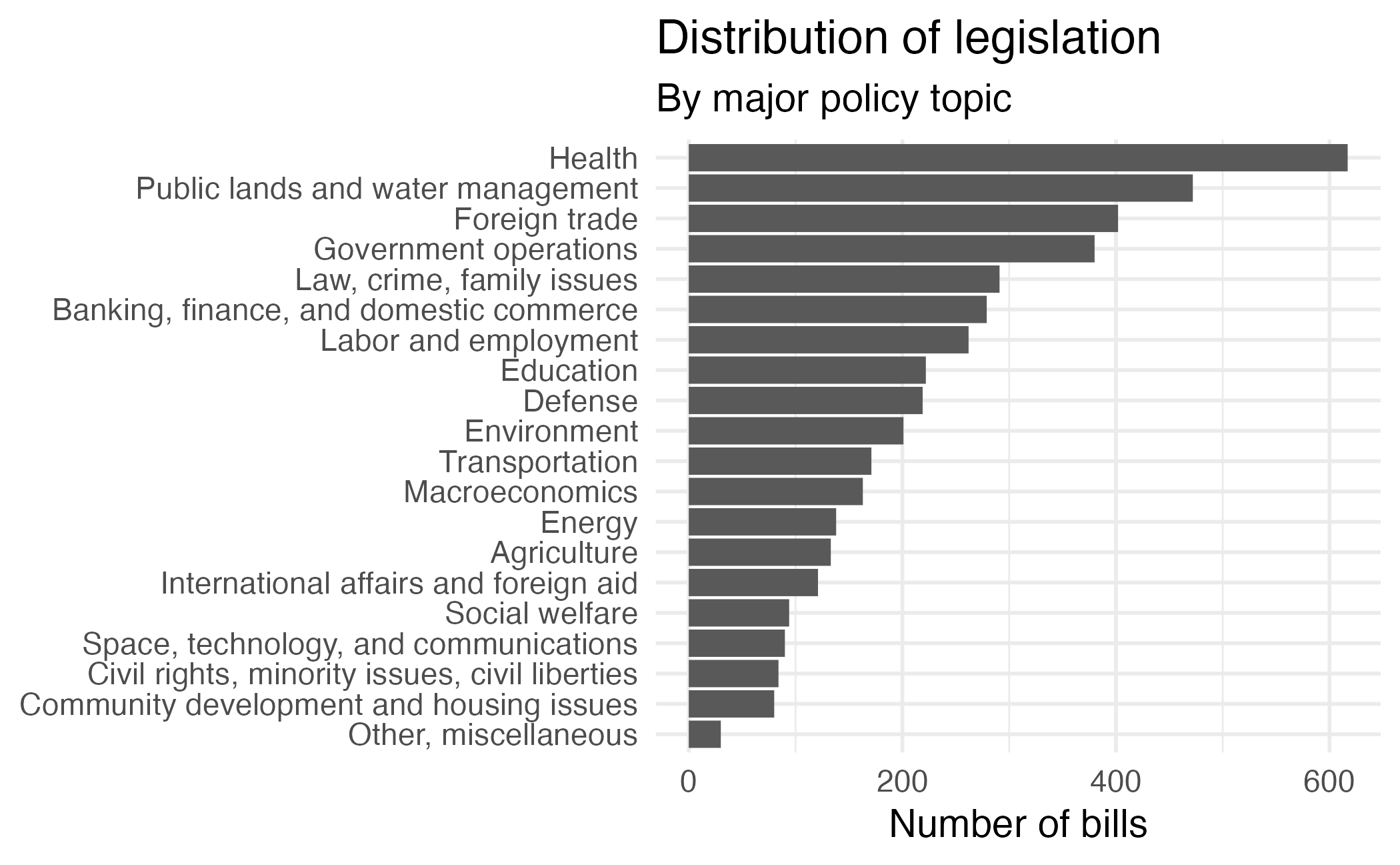
$ label <fct> "Foreign trade", "Foreign trade", "Foreign trade", "Foreign t…Text analysis: supervised classification
Lecture 27
Dr. Benjamin Soltoff
Cornell University
INFO 2950 - Spring 2024
May 2, 2024
Announcements
Announcements
- Presentations tomorrow
- Team projects due Tuesday
- Homework 08 and slip days
Supervised text classification
Supervised learning
- Hand-code a small set of documents \(N =\) 1,000
- Train a machine learning model on the hand-coded data
- Evaluate the effectiveness of the machine learning model
- Apply the final model to the remaining set of documents \(N =\) 1,000,000
USCongress
[1] "To suspend temporarily the duty on Fast Magenta 2 Stage."
[2] "To suspend temporarily the duty on Fast Black 286 Stage."
[3] "To suspend temporarily the duty on mixtures of Fluazinam."
[4] "To reduce temporarily the duty on Prodiamine Technical."
[5] "To amend the Immigration and Nationality Act in regard to Caribbean-born immigrants."
[6] "To amend title 38, United States Code, to extend the eligibility for housing loans guaranteed by the Secretary of Veterans Affairs under the Native American Housing Loan Pilot Program to veterans who are married to Native Americans."Split the data set
set.seed(123)
# convert response variable to factor
congress <- congress |>
mutate(major = factor(x = major, levels = major, labels = label))
# split into training and testing sets
congress_split <- initial_split(data = congress, strata = major, prop = .8)
congress_split<Training/Testing/Total>
<3558/891/4449>Class imbalance
Preprocessing the data frame
Review the preprocessed data frame
# A tibble: 540 × 501
major tfidf_text_1 tfidf_text_10 tfidf_text_11 tfidf_text_18 tfidf_text_1965
<fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Forei… 0 0 0 0 0
2 Forei… 0 0 0 0 0
3 Forei… 0 0 0 0 0
4 Forei… 0 0 0 0 0
5 Forei… 0 0 0 0 0
6 Forei… 0 0 0 0 0
7 Forei… 0 0 0 0 0
8 Forei… 0 0 0 0 0
9 Forei… 0 0 0 0 0
10 Forei… 0 0 0 0 0
# ℹ 530 more rows
# ℹ 495 more variables: tfidf_text_1974 <dbl>, tfidf_text_1986 <dbl>,
# tfidf_text_2 <dbl>, tfidf_text_2000 <dbl>, tfidf_text_2001 <dbl>,
# tfidf_text_2002 <dbl>, tfidf_text_2003 <dbl>, tfidf_text_23 <dbl>,
# tfidf_text_3 <dbl>, tfidf_text_30 <dbl>, tfidf_text_38 <dbl>,
# tfidf_text_4 <dbl>, tfidf_text_49 <dbl>, tfidf_text_5 <dbl>,
# tfidf_text_abuse <dbl>, tfidf_text_access <dbl>, …Establish a baseline
null_classification <- null_model() |>
set_engine("parsnip") |>
set_mode("classification")
null_cv <- workflow() |>
add_recipe(congress_rec) |>
add_model(null_classification) |>
fit_resamples(
congress_folds
)
null_cv |>
collect_metrics()# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 accuracy multiclass 0.0899 10 0.00396 Preprocessor1_Model1
2 roc_auc hand_till 0.5 10 0 Preprocessor1_Model1Define the model
Train the model
tree_cv_metrics <- collect_metrics(tree_cv)
tree_cv_predictions <- collect_predictions(tree_cv)
tree_cv_metrics# A tibble: 3 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 accuracy multiclass 0.432 10 0.00689 Preprocessor1_Model1
2 brier_class multiclass 0.401 10 0.00440 Preprocessor1_Model1
3 roc_auc hand_till 0.766 10 0.00706 Preprocessor1_Model1Confusion matrix
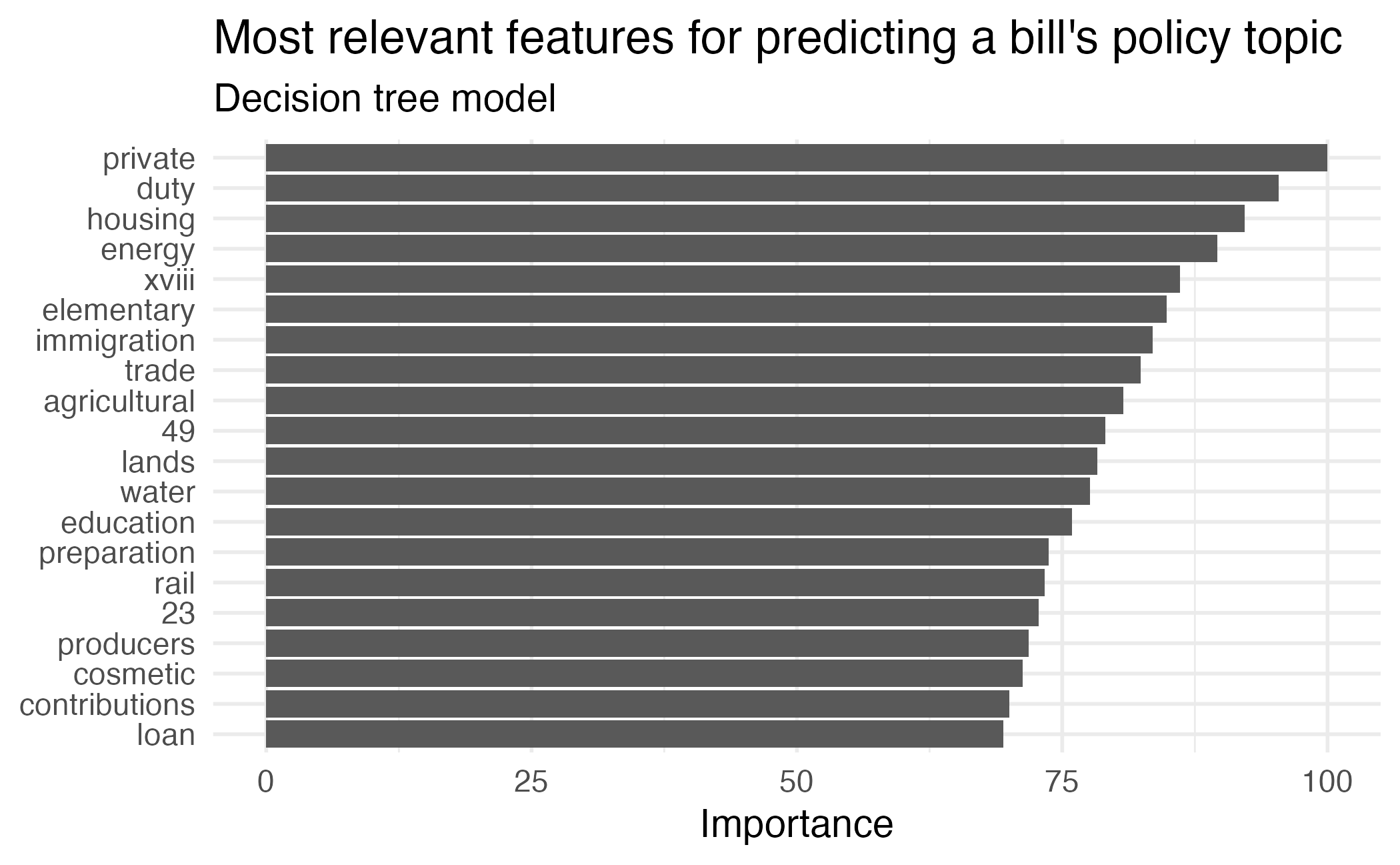
Feature importance
Application exercise


ae-25
- Go to the course GitHub org and find your
ae-25(repo name will be suffixed with your GitHub name). - Clone the repo in RStudio Workbench, open the Quarto document in the repo, and follow along and complete the exercises.
- Render, commit, and push your edits by the AE deadline – end of tomorrow
Recap
- Supervised ML with text features does not have to be that different from ordinary ML
- Need to quantify text into numeric variables through tokenization and other processes
- Tokenization can produce a substantial number of features – unless computing power is unlimited, you will need to restrict the number of variables using some methodology
- Use variable importance measures to assess how important specific tokens are to the predictive model
Do we really need this?