| ID | Text |
|---|---|
| 1 | The dog ate the cat |
| 2 | The cat ate the mouse |
| 3 | Mice are silly |
| 4 | The cheese was delicious |
Text analysis: fundamentals and sentiment analysis
Lecture 26
Dr. Benjamin Soltoff
Cornell University
INFO 2950 - Spring 2024
April 30, 2024
Announcements
Announcements
- Homework 07
- Exam 02 (the Final exam)
- Project presentations on Friday
Core text data workflows
Basic workflow for text analysis
- Obtain your text sources
- Extract documents and move into a corpus
- Transformation
- Extract features
- Perform analysis
Obtain your text sources
- Web sites/APIs
- Databases
- PDF documents
- Digital scans of printed materials
Extract documents and move into a corpus
- Text corpus
- Typically stores the text as a raw character string with metadata and details stored with the text
Transformation
- Tag segments of speech for part-of-speech (nouns, verbs, adjectives, etc.) or entity recognition (person, place, company, etc.)
- Standard text processing
- Convert to lower case
- Remove punctuation
- Remove numbers
- Remove stopwords
- Remove domain-specific stopwords
- Stemming
Extract features
Convert the text string into some sort of quantifiable measures
Bag-of-words model
| ID | are | ate | cat | cheese | delicious | dog | mice | mouse | silly | the | was |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 2 | 0 |
| 2 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
- Term frequency vector
- Term-document matrix
- Ignores context
- Sparse data structure
Word embeddings
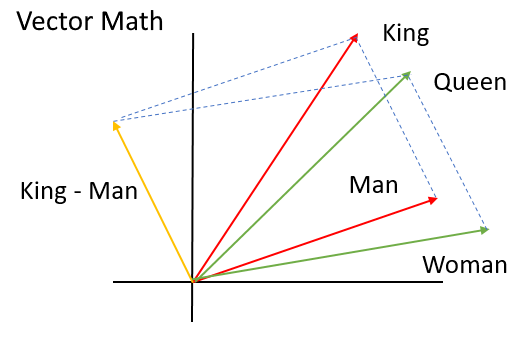
Word embedding: a mathematical representation of a word in a continuous vector space
- Dense data structure
- Captures context
- Semantic similarity
Word embeddings
Consumer complaints to the CFPB
[1] "transworld systems inc. \nis trying to collect a debt that is not mine, not owed and is inaccurate."
[2] "I would like to request the suppression of the following items from my credit report, which are the result of my falling victim to identity theft. This information does not relate to [ transactions that I have made/accounts that I have opened ], as the attached supporting documentation can attest. As such, it should be blocked from appearing on my credit report pursuant to section 605B of the Fair Credit Reporting Act."
[3] "Over the past 2 weeks, I have been receiving excessive amounts of telephone calls from the company listed in this complaint. The calls occur between XXXX XXXX and XXXX XXXX to my cell and at my job. The company does not have the right to harass me at work and I want this to stop. It is extremely distracting to be told 5 times a day that I have a call from this collection agency while at work."
[4] "I was sold access to an event digitally, of which I have all the screenshots to detail the transactions, transferred the money and was provided with only a fake of a ticket. I have reported this to paypal and it was for the amount of {$21.00} including a {$1.00} fee from paypal. \n\nThis occured on XX/XX/2019, by paypal user who gave two accounts : 1 ) XXXX 2 ) XXXX XXXX" Sparse matrix structure
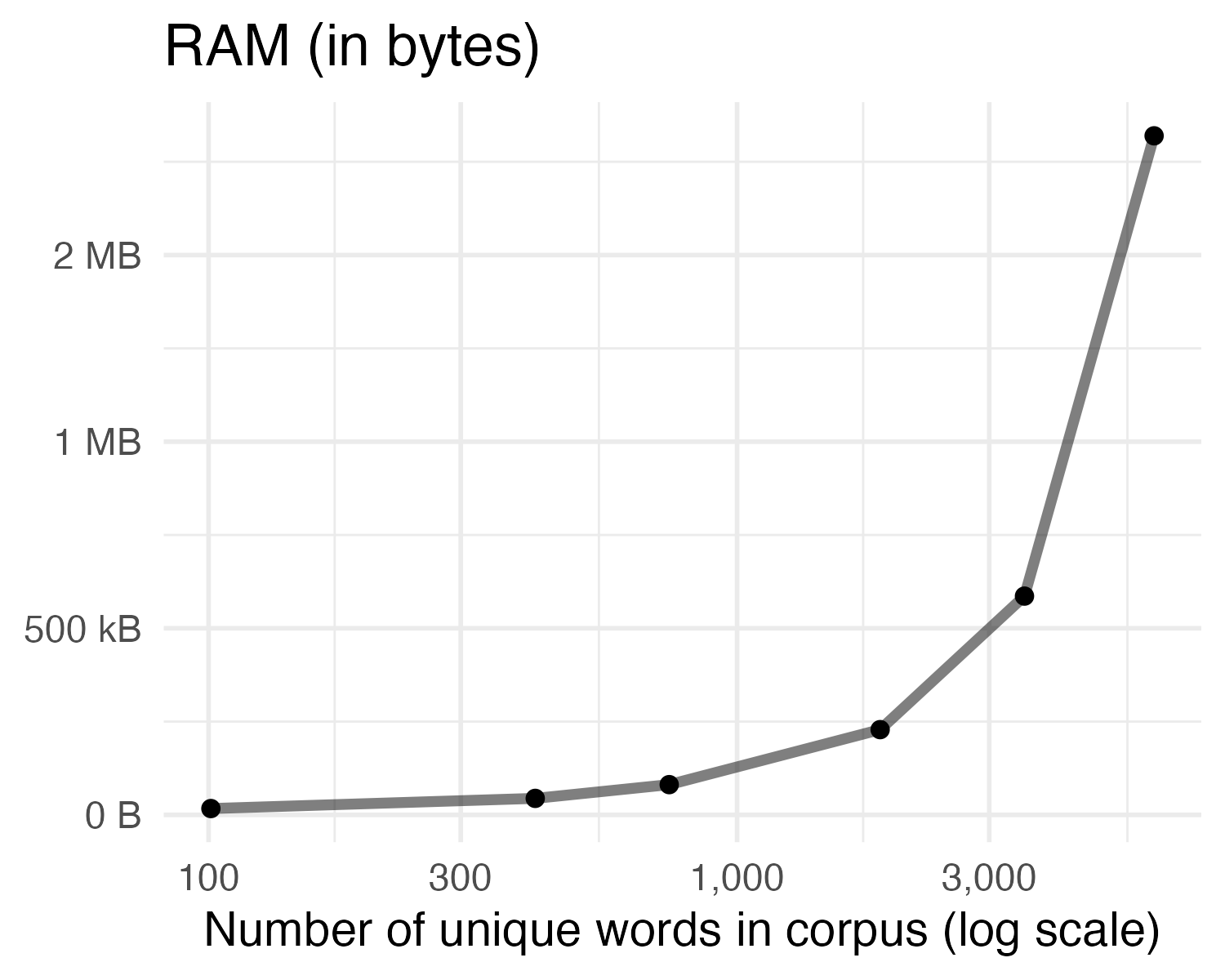
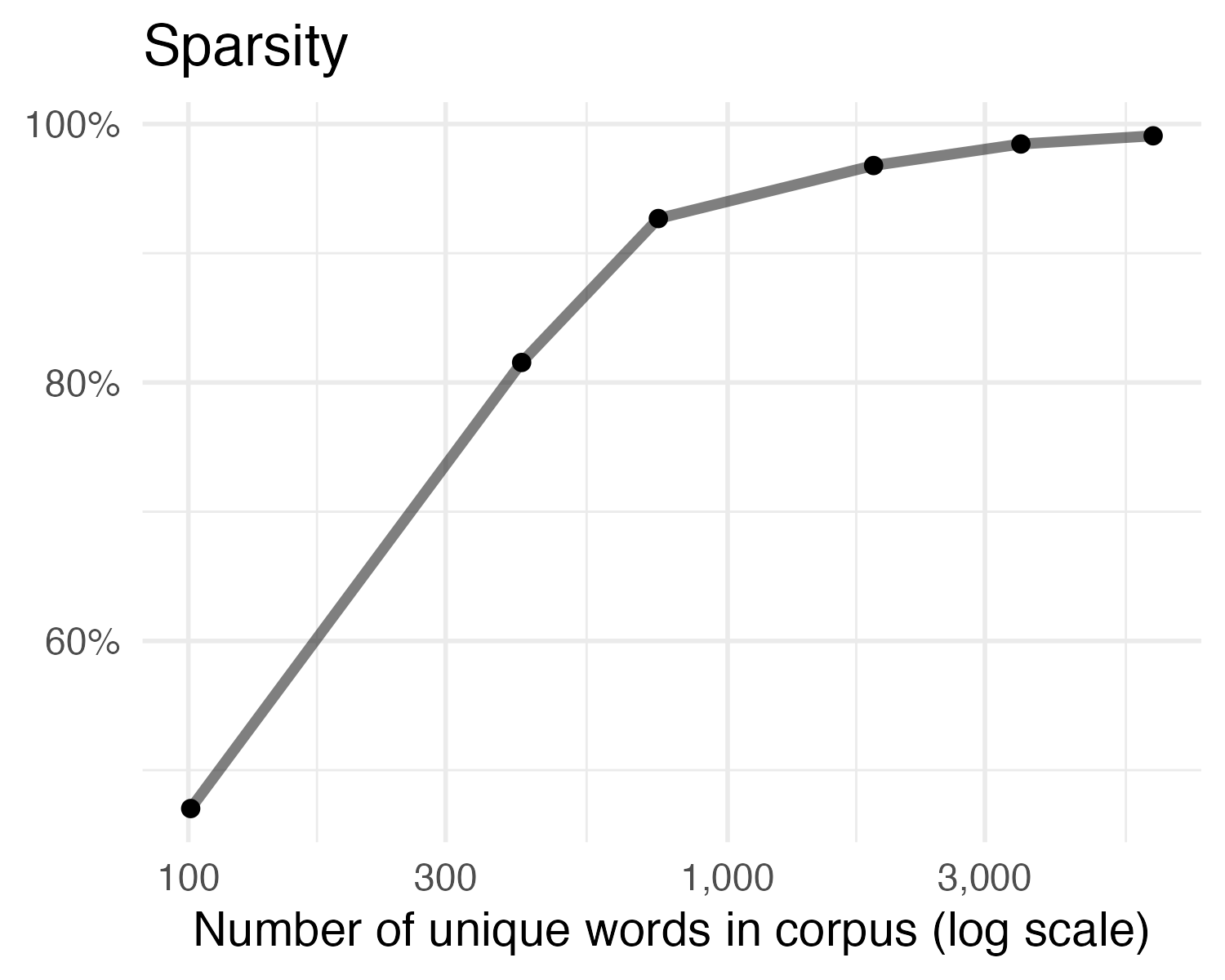
Document-feature matrix of: 117,214 documents, 46,099 features (99.88% sparse) and 0 docvars.
features
docs account auto bank call charg chase dai date dollar
3113204 1 1 2 2 1 1 1 3 1 1
3113208 0 1 0 6 3 5 0 0 1 1
3113804 0 0 0 0 0 0 0 2 2 0
3113805 0 1 0 0 0 0 0 0 0 0
3113807 0 2 0 0 0 1 0 0 0 0
3113808 0 0 0 0 0 0 0 0 0 0
[ reached max_ndoc ... 117,208 more documents, reached max_nfeat ... 46,089 more features ]Sparsity of text corpa
Generating word embeddings
- Dimension reduction
- Principal components analysis (PCA)
- Singular value decomposition (SVD)
- Probabilistic models
- Neural networks
- Word2Vec
- GloVe
- BERT
- ELMO
- Custom-generated or pre-trained
GloVe
- Pre-trained word vector representations
- Measured using co-occurrence statistics (how frequently words occur in proximity to each other)
- Four versions
- Wikipedia (2014) - 6 billion tokens, 400 thousand words
- Twitter - 27 billion tokens, 2 billion tweets, 1.2 million words
- Common Crawl - 42 billion tokens, 1.9 million words
- Common Crawl - 840 billion tokens, 2.2 million words
GloVe 6b (100 dimensions)
# A tibble: 400,000 × 101
token d1 d2 d3 d4 d5 d6 d7 d8 d9
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 "the" -0.0382 -0.245 0.728 -0.400 0.0832 0.0440 -0.391 0.334 -0.575
2 "," -0.108 0.111 0.598 -0.544 0.674 0.107 0.0389 0.355 0.0635
3 "." -0.340 0.209 0.463 -0.648 -0.384 0.0380 0.171 0.160 0.466
4 "of" -0.153 -0.243 0.898 0.170 0.535 0.488 -0.588 -0.180 -1.36
5 "to" -0.190 0.0500 0.191 -0.0492 -0.0897 0.210 -0.550 0.0984 -0.201
6 "and" -0.0720 0.231 0.0237 -0.506 0.339 0.196 -0.329 0.184 -0.181
7 "in" 0.0857 -0.222 0.166 0.134 0.382 0.354 0.0129 0.225 -0.438
8 "a" -0.271 0.0440 -0.0203 -0.174 0.644 0.712 0.355 0.471 -0.296
9 "\"" -0.305 -0.236 0.176 -0.729 -0.283 -0.256 0.266 0.0253 -0.0748
10 "'s" 0.589 -0.202 0.735 -0.683 -0.197 -0.180 -0.392 0.342 -0.606
# ℹ 399,990 more rows
# ℹ 91 more variables: d10 <dbl>, d11 <dbl>, d12 <dbl>, d13 <dbl>, d14 <dbl>,
# d15 <dbl>, d16 <dbl>, d17 <dbl>, d18 <dbl>, d19 <dbl>, d20 <dbl>,
# d21 <dbl>, d22 <dbl>, d23 <dbl>, d24 <dbl>, d25 <dbl>, d26 <dbl>,
# d27 <dbl>, d28 <dbl>, d29 <dbl>, d30 <dbl>, d31 <dbl>, d32 <dbl>,
# d33 <dbl>, d34 <dbl>, d35 <dbl>, d36 <dbl>, d37 <dbl>, d38 <dbl>,
# d39 <dbl>, d40 <dbl>, d41 <dbl>, d42 <dbl>, d43 <dbl>, d44 <dbl>, …Fairness in word embeddings
- Word embeddings learn semantics and meaning from human speech
- If the text is biased, then the embeddings will also contain bias
- Terms associated with women are more associated with the arts and terms associated with men are more associated with science.1
- Even large language models (LLMs) trained on vast corpa of human-generated text do not reflect representative or diverse viewpoints.2
- Sentiment analysis utilizing off-the-shelf word embeddings can score text such as “Let’s go get Italian food” more positively than “Let’s go get Mexican food”3
Perform analysis
- Basic
- Word frequency
- Collocation
- Dictionary tagging
- Advanced
- Document classification
- Corpora comparison
- Topic modeling
tidytext
tidytext
- Using tidy data principles can make many text mining tasks easier, more effective, and consistent with tools already in wide use
- Learn more at tidytextmining.com

What is tidy text?
text <- c(
"Yeah, with a boy like that it's serious",
"There's a boy who is so wonderful",
"That girls who see him cannot find back home",
"And the gigolos run like spiders when he comes",
"'Cause he is Eros and he's Apollo",
"Girls, with a boy like that it's serious",
"Senoritas, don't follow him",
"Soon, he will eat your hearts like cereals",
"Sweet Lolitas, don't go",
"You're still young",
"But every night they fall like dominoes",
"How he does it, only heaven knows",
"All the other men turn gay wherever he goes (wow!)"
)
text [1] "Yeah, with a boy like that it's serious"
[2] "There's a boy who is so wonderful"
[3] "That girls who see him cannot find back home"
[4] "And the gigolos run like spiders when he comes"
[5] "'Cause he is Eros and he's Apollo"
[6] "Girls, with a boy like that it's serious"
[7] "Senoritas, don't follow him"
[8] "Soon, he will eat your hearts like cereals"
[9] "Sweet Lolitas, don't go"
[10] "You're still young"
[11] "But every night they fall like dominoes"
[12] "How he does it, only heaven knows"
[13] "All the other men turn gay wherever he goes (wow!)"What is tidy text?
# A tibble: 13 × 2
line text
<int> <chr>
1 1 Yeah, with a boy like that it's serious
2 2 There's a boy who is so wonderful
3 3 That girls who see him cannot find back home
4 4 And the gigolos run like spiders when he comes
5 5 'Cause he is Eros and he's Apollo
6 6 Girls, with a boy like that it's serious
7 7 Senoritas, don't follow him
8 8 Soon, he will eat your hearts like cereals
9 9 Sweet Lolitas, don't go
10 10 You're still young
11 11 But every night they fall like dominoes
12 12 How he does it, only heaven knows
13 13 All the other men turn gay wherever he goes (wow!)What is tidy text?
Counting words
Application exercise

ae-24
- Go to the course GitHub org and find your
ae-24(repo name will be suffixed with your GitHub name). - Clone the repo in RStudio Workbench, open the Quarto document in the repo, and follow along and complete the exercises.
- Render, commit, and push your edits by the AE deadline – end of tomorrow
Recap
- tidytext allows you to structure text data in a format conducive to exploratory analysis and wrangling/visualization with tidyverse
- Tokenizing is a process of converting raw character strings to recognizable features
- Remove non-informative stop words to reduce noise in the text data
- Dictionary-based sentiment analysis provides a rough classification of text into positive/negative sentiments
We’re almost done!