library(tidyverse)
library(tidytext)
library(ggtext)
library(widyr)
library(ggraph)
library(igraph)
theme_set(theme_minimal(base_size = 13))Do not throw away your shot: Text mining and Hamilton
Tutorial
Text analysis
Use tidytext to explore the Hamilton lyrics.
Before TikTok came for Lin-Manuel Miranda, there was Hamilton.
@okayelisabeth lin❤️😽 #fyp #linmanuelmiranda #hamilton ♬ original sound - elisabeth


One of the nice things about the musical is that it is sung-through, so the lyrics contain essentially all of the dialogue. This provides an interesting opportunity to use the tidytext package to analyze the lyrics.
hamilton <- read_csv(file = "data/hamilton.csv") |>
mutate(song_name = parse_factor(song_name))
glimpse(hamilton)Rows: 3,532
Columns: 5
$ song_number <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ song_name <fct> "Alexander Hamilton", "Alexander Hamilton", "Alexander Ham…
$ line_num <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,…
$ line <chr> "How does a bastard, orphan, son of a whore and a", "Scots…
$ speaker <chr> "Aaron Burr", "Aaron Burr", "Aaron Burr", "Aaron Burr", "J…Along with the lyrics, we also know the singer (speaker) of each line of dialogue. This will be helpful if we want to perform analysis on a subset of singers.
Convert to tidytext format
Currently, hamilton is stored as one-row-per-line of lyrics. The definition of a single “line” is somewhat arbitrary. For substantial analysis, we will convert the corpus to a tidy-text data frame of one-row-per-token. Initially, we will use unnest_tokens() to tokenize all unigrams.
hamilton_tidy <- unnest_tokens(tbl = hamilton, output = word, input = line)
hamilton_tidy# A tibble: 21,142 × 5
song_number song_name line_num speaker word
<dbl> <fct> <dbl> <chr> <chr>
1 1 Alexander Hamilton 1 Aaron Burr how
2 1 Alexander Hamilton 1 Aaron Burr does
3 1 Alexander Hamilton 1 Aaron Burr a
4 1 Alexander Hamilton 1 Aaron Burr bastard
5 1 Alexander Hamilton 1 Aaron Burr orphan
6 1 Alexander Hamilton 1 Aaron Burr son
7 1 Alexander Hamilton 1 Aaron Burr of
8 1 Alexander Hamilton 1 Aaron Burr a
9 1 Alexander Hamilton 1 Aaron Burr whore
10 1 Alexander Hamilton 1 Aaron Burr and
# ℹ 21,132 more rowsRemember that by default, unnest_tokens() automatically converts all text to lowercase and strips out punctuation.
Length of songs by words
An initial check reveals the length of each song in terms of the number of words in its lyrics.
hamilton_tidy |>
mutate(song_name = fct_rev(song_name)) |>
ggplot(mapping = aes(y = song_name)) +
geom_bar() +
labs(
title = "Length of songs in Hamilton",
x = "Song length (in words)",
y = NULL,
caption = "Source: Genius"
)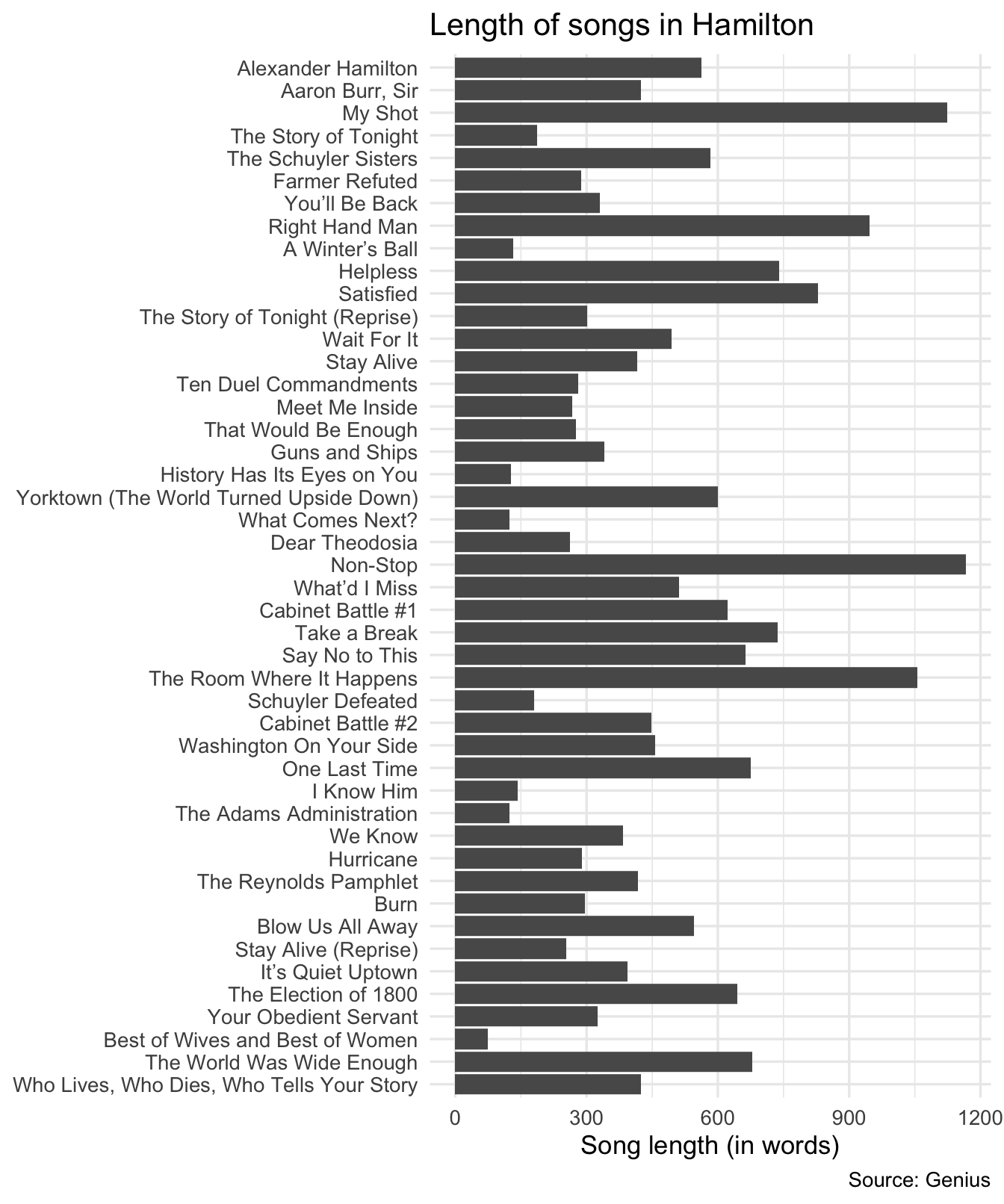
As a function of number of words, “Non-Stop” is the longest song in the musical.
Stop words
Of course not all words are equally important. Consider the 10 most frequent words in the lyrics:
hamilton_tidy |>
count(word) |>
arrange(desc(n))# A tibble: 2,929 × 2
word n
<chr> <int>
1 the 848
2 i 639
3 you 578
4 to 544
5 a 471
6 and 383
7 in 317
8 it 294
9 of 274
10 my 259
# ℹ 2,919 more rowsNot particularly informative. We can identify a list of stop_words then remove them via anti_join().
# get a set of stop words
stop_words# A tibble: 1,149 × 2
word lexicon
<chr> <chr>
1 a SMART
2 a's SMART
3 able SMART
4 about SMART
5 above SMART
6 according SMART
7 accordingly SMART
8 across SMART
9 actually SMART
10 after SMART
# ℹ 1,139 more rows# remove stop words
hamilton_tidy <- anti_join(x = hamilton_tidy, y = stop_words)
hamilton_tidy |>
count(word) |>
slice_max(n = 20, order_by = n) |>
mutate(word = fct_reorder(.f = word, .x = n)) |>
ggplot(aes(x = n, y = word)) +
geom_col() +
labs(
title = "Frequency of Hamilton lyrics",
x = NULL,
y = NULL
)
Now the words seem more relevant to the specific story being told in the musical.
Words used most by each cast member
Since we know which singer performs each line, we can examine the relative significance of different words to different characters. Term frequency-inverse document frequency (tf-idf) is a simple metric for measuring the importance of specific words to a corpus. Here let’s calculate the top ten words for each member of the principal cast.
# principal cast via Wikipedia
principal_cast <- c(
"Hamilton", "Eliza", "Burr", "Angelica", "Washington",
"Lafayette", "Jefferson", "Mulligan", "Madison",
"Laurens", "Philip", "Peggy", "Maria", "King George"
)
# calculate tf-idf scores for words sung by the principal cast
hamilton_tf_idf <- hamilton_tidy |>
filter(speaker %in% principal_cast) |>
mutate(speaker = parse_factor(x = speaker, levels = principal_cast)) |>
count(speaker, word) |>
bind_tf_idf(term = word, document = speaker, n = n)
# visualize the top N terms per character by tf-idf score
hamilton_tf_idf |>
group_by(speaker) |>
slice_max(n = 10, order_by = tf_idf, with_ties = FALSE) |>
ggplot(mapping = aes(x = tf_idf, y = word)) +
geom_col() +
labs(
title = "Most important words in *Hamilton*",
subtitle = "Principal cast only",
x = "tf-idf",
y = NULL,
caption = "Source: Genius"
) +
facet_wrap(facets = vars(speaker), scales = "free") +
theme(plot.title = element_markdown())
Not very functional sorted alphabetically. Let’s sort all the facets from highest to lowest tf-idf scores.
# visualize the top N terms per character by tf-idf score
hamilton_tf_idf |>
group_by(speaker) |>
slice_max(n = 10, order_by = tf_idf, with_ties = FALSE) |>
# create word as a factor column ordered by n
mutate(word = fct_reorder(.f = word, .x = n)) |>
ggplot(mapping = aes(x = tf_idf, y = word)) +
geom_col() +
labs(
title = "Most important words in *Hamilton*",
subtitle = "Principal cast only",
x = "tf-idf",
y = NULL,
caption = "Source: Genius"
) +
facet_wrap(facets = vars(speaker), scales = "free") +
theme(plot.title = element_markdown())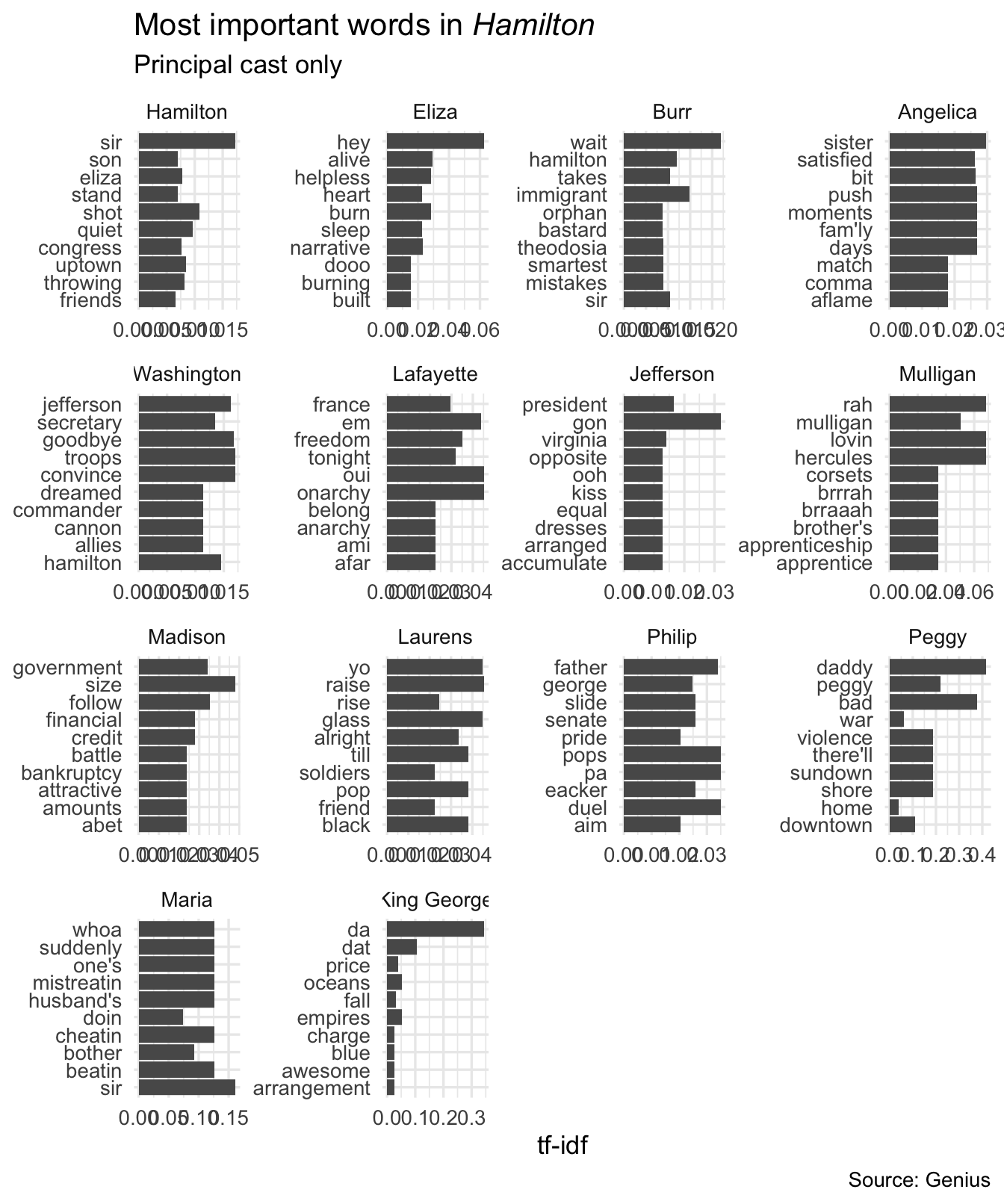
Still does not look right. The problem is that some tokens appear in multiple facets but with different tf-idf scores (and different orders). We need to order the rows within each facet independently. But ggplot2 does not support this operation. How can we do so? Using tidytext::reorder_within() and tidytext::scale_y_reordered().
hamilton_tf_idf |>
group_by(speaker) |>
slice_max(n = 10, order_by = tf_idf, with_ties = FALSE) |>
# create word as a factor column ordered by n
mutate(word = fct_reorder(.f = word, .x = n)) |>
# resolve ambiguities when same word appears for different characters
ungroup() |>
mutate(word = reorder_within(x = word, by = tf_idf, within = speaker)) |>
ggplot(mapping = aes(x = tf_idf, y = word)) +
geom_col() +
scale_y_reordered() +
labs(
title = "Most important words in *Hamilton*",
subtitle = "Principal cast only",
x = "tf-idf",
y = NULL,
caption = "Source: Genius"
) +
facet_wrap(facets = vars(speaker), scales = "free") +
theme(plot.title = element_markdown())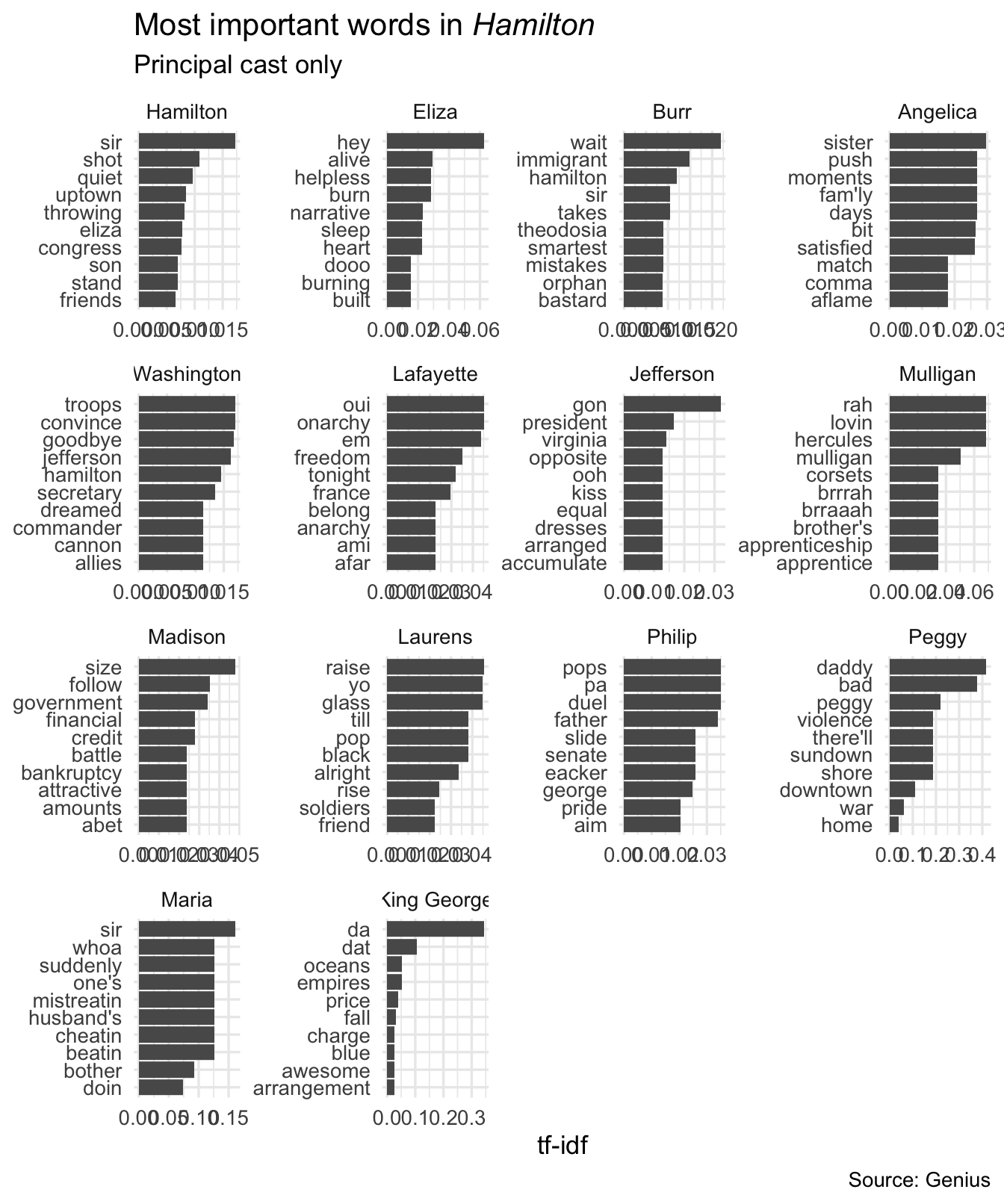
Again, some expected results stick out. Hamilton is always singing about not throwing away his shot, Eliza is helplessly in love with Alexander, while Burr regrets not being “in the room where it happens”. And don’t forget King George’s love songs to his wayward children.

Sentiment analysis
Sentiment analysis utilizes the text of the lyrics to classify content as positive or negative. Dictionary-based methods use pre-generated lexicons of words independently coded as positive/negative. We can combine one of these dictionaries with the Hamilton tidy-text data frame using inner_join() to identify words with sentimental affect, and further analyze trends.
Here we use the afinn dictionary which classifies 2,477 words on a scale of \([-5, +5]\).
# afinn dictionary
get_sentiments(lexicon = "afinn")# A tibble: 2,477 × 2
word value
<chr> <dbl>
1 abandon -2
2 abandoned -2
3 abandons -2
4 abducted -2
5 abduction -2
6 abductions -2
7 abhor -3
8 abhorred -3
9 abhorrent -3
10 abhors -3
# ℹ 2,467 more rowshamilton_afinn <- hamilton_tidy |>
# join with sentiment dictionary
inner_join(y = get_sentiments(lexicon = "afinn")) |>
# create row id and cumulative sentiment over the entire corpus
mutate(
cum_sent = cumsum(value),
id = row_number()
)
hamilton_afinn# A tibble: 1,109 × 8
song_number song_name line_num speaker word value cum_sent id
<dbl> <fct> <dbl> <chr> <chr> <dbl> <dbl> <int>
1 1 Alexander Hamilton 1 Aaron Burr bast… -5 -5 1
2 1 Alexander Hamilton 1 Aaron Burr whore -4 -9 2
3 1 Alexander Hamilton 2 Aaron Burr forg… -1 -10 3
4 1 Alexander Hamilton 4 Aaron Burr hero 2 -8 4
5 1 Alexander Hamilton 7 John Laur… smar… 2 -6 5
6 1 Alexander Hamilton 11 Thomas Je… stru… -2 -8 6
7 1 Alexander Hamilton 12 Thomas Je… long… -1 -9 7
8 1 Alexander Hamilton 13 Thomas Je… steal -2 -11 8
9 1 Alexander Hamilton 17 James Mad… pain -2 -13 9
10 1 Alexander Hamilton 18 Burr insa… -2 -15 10
# ℹ 1,099 more rowsFirst, we can examine the sentiment of each song individually by calculating the average sentiment of each word in the song.
# sentiment by song
hamilton_afinn |>
group_by(song_name) |>
summarize(sent = mean(value)) |>
mutate(song_name = fct_rev(song_name)) |>
ggplot(mapping = aes(x = sent, y = song_name, fill = sent)) +
geom_col() +
scale_fill_viridis_c() +
labs(
title = "Positive/negative sentiment in *Hamilton*",
subtitle = "By song",
x = "Average sentiment",
y = NULL,
fill = "Average\nsentiment",
caption = "Source: Genius"
) +
theme(
plot.title = element_markdown(),
legend.position = "none"
)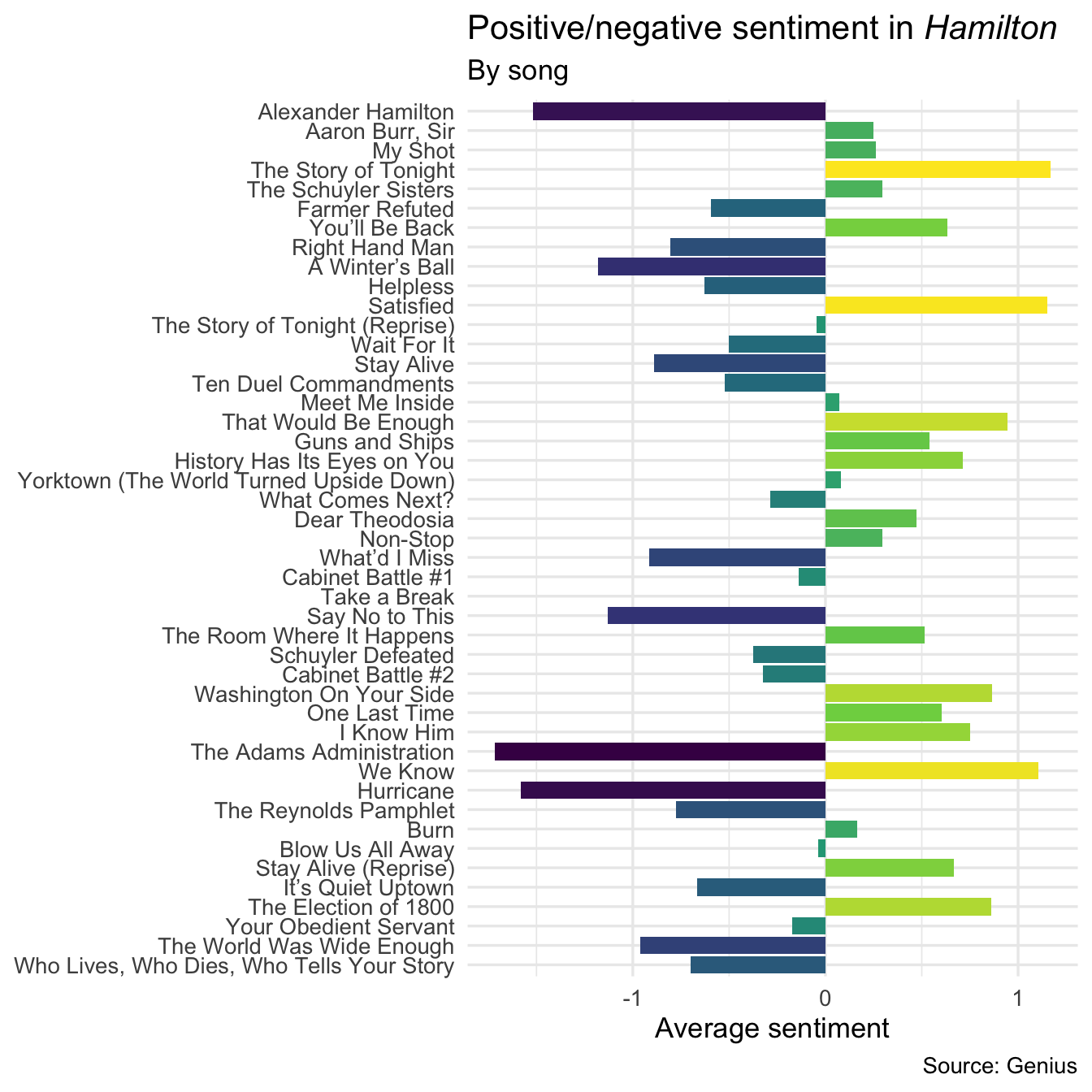
Again, the general themes of the songs come across in this analysis. “Alexander Hamilton” introduces Hamilton’s tragic backstory and difficult circumstances before emigrating to New York. “Dear Theodosia” is a love letter from Burr and Hamilton, promising to make the world a better place for their respective children.
However, this also illustrates some problems with dictionary-based sentiment analysis. Consider the back-to-back songs “Helpless” and “Satisfied”.
“Helpless” depicts Eliza and Alexander falling in love with one another and getting married, while “Satisfied” recounts these same events from the perspective of Eliza’s sister Angelica who suppresses her own feelings for Hamilton out of a sense of duty to her sister. From the perspective of the listener, “Helpless” is the far more positive song of the pair. Why are they reversed based on the textual analysis?
get_sentiments(lexicon = "afinn") |>
filter(word %in% c("helpless", "satisfied"))# A tibble: 2 × 2
word value
<chr> <dbl>
1 helpless -2
2 satisfied 2Herein lies the problem with dictionary-based methods. The AFINN lexicon codes “helpless” as a negative term and “satisfied” as a positive term. On their own this makes sense, but in the context of the music clearly Eliza is “helplessly” in love while Angelica will in fact never be “satisfied” because she cannot be with Alexander. A dictionary-based sentiment classification will always miss these nuances in language.
We could also examine the general disposition of each speaker based on the sentiment of their lyrics. Consider the principal cast below:
hamilton_afinn |>
filter(speaker %in% principal_cast) |>
# calculate average sentiment by character with standard error
group_by(speaker) |>
summarize(
sent = mean(value),
se = sd(value) / n()
) |>
# generate plot sorted from positive to negative
ggplot(mapping = aes(y = fct_reorder(speaker, sent), x = sent, fill = sent)) +
geom_pointrange(mapping = aes(
xmin = sent - 2 * se,
xmax = sent + 2 * se
)) +
labs(
title = "Positive/negative sentiment in *Hamilton*",
subtitle = "By speaker",
x = "Average sentiment",
y = NULL,
caption = "Source: Genius"
) +
theme(
plot.title = element_markdown(),
legend.position = "none"
)
Given his generally neutral sentiment, Aaron Burr clearly follows his own guidance.


Also, can we please note Peggy’s general pessimism?

Tracking the cumulative sentiment across the entire musical, it’s easy to identify the high and low points.
# get first row for each song
hamilton_songs <- hamilton_afinn |>
group_by(song_number) |>
filter(id == min(id)) |>
select(song_number, id, song_name)
hamilton_songs# A tibble: 45 × 3
# Groups: song_number [45]
song_number id song_name
<dbl> <int> <fct>
1 1 1 Alexander Hamilton
2 2 26 Aaron Burr, Sir
3 3 46 My Shot
4 4 84 The Story of Tonight
5 5 96 The Schuyler Sisters
6 6 123 Farmer Refuted
7 7 150 You’ll Be Back
8 8 169 Right Hand Man
9 9 205 A Winter’s Ball
10 10 216 Helpless
# ℹ 35 more rowsggplot(data = hamilton_afinn, mapping = aes(x = id, y = cum_sent)) +
geom_line() +
# label the start of each song
scale_x_reverse(
breaks = pull(.data = hamilton_songs, id),
labels = pull(.data = hamilton_songs, song_name)
) +
labs(
title = "Positive/negative sentiment in *Hamilton*",
x = NULL,
y = "Cumulative sentiment",
caption = "Source: Genius"
) +
# transpose to be able to fit song titles on the graph
coord_flip() +
theme(
panel.grid.minor.y = element_blank(),
plot.title = element_markdown()
)
After the initial drop from “Alexander Hamilton”, the next peaks in the graph show several positive events in Hamilton’s life: meeting his friends, becoming Washington’s secretary, and meeting and marrying Eliza. The musical experiences a drop in tone during the rough years of the revolution and Hamilton’s dismissal back to New York, then rebounds as the revolutionaries close in on victory at Yorktown. Hamilton’s challenges as a member of Washington’s cabinet and rivalry with Jefferson are captured in the up-and-down swings in the graph, rises up with “One Last Time” and Hamilton writing Washington’s Farewell Address, dropping once again with “Hurricane” and the revelation of Hamilton’s affair, rising as Alexander and Eliza reconcile before finally descending once more upon Hamilton’s death in his duel with Burr.
Pairs of words
Finally we can examine the colocation of pairs of words to look for common usage.
# calculate all pairs of words in the musical
hamilton_pair <- hamilton |>
unnest_tokens(
output = word,
input = line,
token = "ngrams",
n = 2
) |>
separate(
col = word,
into = c("word1", "word2"),
sep = " "
) |>
filter(
!word1 %in% stop_words$word,
!word2 %in% stop_words$word
) |>
drop_na(word1, word2) |>
count(word1, word2, sort = TRUE)
# filter for only relatively common combinations
bigram_graph <- hamilton_pair |>
filter(n > 3) |>
graph_from_data_frame()
# draw a network graph
set.seed(1776) # New York City
ggraph(bigram_graph, layout = "fr") +
geom_edge_link(aes(edge_alpha = n, edge_width = n), show.legend = FALSE, alpha = .5) +
geom_node_point(color = "#0052A5", size = 3, alpha = .5) +
geom_node_text(aes(label = name), vjust = 1.5) +
ggtitle("Word Network in Lin-Manuel Miranda's *Hamilton*") +
theme_void() +
theme(plot.title = element_markdown())
It’s apparent there are several major themes detected through this approach, including the Hamilton/Jefferson relationship, “Aaron Burr, sir”, Philip’s song with his mother (un, deux, trois, quatre, …), the rising up of the colonies, and those young, scrappy, and hungry men.
Acknowledgments
- This page is derived in part from A Sentiment Analysis of Hamilton: The broom Where it Happens / When are these #rcatladies gonna rise up? and licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) License.
- This page is derived in part from Alexander Hamilton: The Breakdown.
- This page is derived in part from Tidytext Analysis and licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) License.
Session information
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.3.2 (2023-10-31)
os macOS Ventura 13.6.6
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/New_York
date 2024-04-23
pandoc 3.1.1 @ /Applications/RStudio.app/Contents/Resources/app/quarto/bin/tools/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
backports 1.4.1 2021-12-13 [1] CRAN (R 4.3.0)
broom 1.0.5 2023-06-09 [1] CRAN (R 4.3.0)
cli 3.6.2 2023-12-11 [1] CRAN (R 4.3.1)
colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)
digest 0.6.34 2024-01-11 [1] CRAN (R 4.3.1)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.3.1)
evaluate 0.23 2023-11-01 [1] CRAN (R 4.3.1)
fansi 1.0.6 2023-12-08 [1] CRAN (R 4.3.1)
farver 2.1.1 2022-07-06 [1] CRAN (R 4.3.0)
fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)
forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)
fs 1.6.3 2023-07-20 [1] CRAN (R 4.3.0)
generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)
ggforce 0.4.1 2022-10-04 [1] CRAN (R 4.3.0)
ggplot2 * 3.5.0 2024-02-23 [1] CRAN (R 4.3.1)
ggraph * 2.1.0 2022-10-09 [1] CRAN (R 4.3.0)
ggrepel 0.9.5 2024-01-10 [1] CRAN (R 4.3.1)
ggtext * 0.1.2 2022-09-16 [1] CRAN (R 4.3.0)
glue 1.7.0 2024-01-09 [1] CRAN (R 4.3.1)
graphlayouts 1.0.2 2023-11-03 [1] CRAN (R 4.3.1)
gridExtra 2.3 2017-09-09 [1] CRAN (R 4.3.0)
gridtext 0.1.5 2022-09-16 [1] CRAN (R 4.3.0)
gtable 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)
here 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)
hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)
htmltools 0.5.7 2023-11-03 [1] CRAN (R 4.3.1)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.3.1)
igraph * 1.6.0 2023-12-11 [1] CRAN (R 4.3.1)
janeaustenr 1.0.0 2022-08-26 [1] CRAN (R 4.3.0)
jsonlite 1.8.8 2023-12-04 [1] CRAN (R 4.3.1)
knitr 1.45 2023-10-30 [1] CRAN (R 4.3.1)
lattice 0.21-9 2023-10-01 [1] CRAN (R 4.3.2)
lifecycle 1.0.4 2023-11-07 [1] CRAN (R 4.3.1)
lubridate * 1.9.3 2023-09-27 [1] CRAN (R 4.3.1)
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)
MASS 7.3-60 2023-05-04 [1] CRAN (R 4.3.2)
Matrix 1.6-1.1 2023-09-18 [1] CRAN (R 4.3.2)
munsell 0.5.1 2024-04-01 [1] CRAN (R 4.3.1)
pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)
polyclip 1.10-6 2023-09-27 [1] CRAN (R 4.3.1)
purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)
R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)
rappdirs 0.3.3 2021-01-31 [1] CRAN (R 4.3.0)
Rcpp 1.0.12 2024-01-09 [1] CRAN (R 4.3.1)
readr * 2.1.5 2024-01-10 [1] CRAN (R 4.3.1)
rlang 1.1.3 2024-01-10 [1] CRAN (R 4.3.1)
rmarkdown 2.25 2023-09-18 [1] CRAN (R 4.3.1)
rprojroot 2.0.4 2023-11-05 [1] CRAN (R 4.3.1)
rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)
scales 1.3.0 2023-11-28 [1] CRAN (R 4.3.1)
sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)
SnowballC 0.7.1 2023-04-25 [1] CRAN (R 4.3.0)
stringi 1.8.3 2023-12-11 [1] CRAN (R 4.3.1)
stringr * 1.5.1 2023-11-14 [1] CRAN (R 4.3.1)
textdata 0.4.4 2022-09-02 [1] CRAN (R 4.3.0)
tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)
tidygraph 1.3.0 2023-12-18 [1] CRAN (R 4.3.1)
tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)
tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)
tidytext * 0.4.1 2023-01-07 [1] CRAN (R 4.3.0)
tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)
timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)
tokenizers 0.3.0 2022-12-22 [1] CRAN (R 4.3.0)
tweenr 2.0.2 2022-09-06 [1] CRAN (R 4.3.0)
tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)
utf8 1.2.4 2023-10-22 [1] CRAN (R 4.3.1)
vctrs 0.6.5 2023-12-01 [1] CRAN (R 4.3.1)
viridis 0.6.4 2023-07-22 [1] CRAN (R 4.3.0)
viridisLite 0.4.2 2023-05-02 [1] CRAN (R 4.3.0)
widyr * 0.1.5 2022-09-13 [1] CRAN (R 4.3.0)
withr 3.0.0 2024-01-16 [1] CRAN (R 4.3.1)
xfun 0.41 2023-11-01 [1] CRAN (R 4.3.1)
xml2 1.3.6 2023-12-04 [1] CRAN (R 4.3.1)
yaml 2.3.8 2023-12-11 [1] CRAN (R 4.3.1)
[1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library
──────────────────────────────────────────────────────────────────────────────