Introduces Application Programming Interfaces (APIs) and how they work.
Modified
March 6, 2024
Obtaining data from the web
There are many ways to obtain data from the Internet. Four major categories are:
click-and-download on the internet as a “flat” file, such as .csv, .xls
install-and-play an API for which someone has written a handy R package
API-query published with an unwrapped API
Scraping implicit in an html website
Click-and-download
In the simplest case, the data you need is already on the internet in a tabular format. There are a couple of strategies here:
Use read.csv or readr::read_csv to read the data straight into R
Use the downloader package or curl from the shell to download the file and store a local copy, then use read_csv or something similar to read the data into R
Even if the file disappears from the internet, you have a local copy cached
Even in this instance, files may need cleaning and transformation when you bring them into R.
Data supplied on the web - APIs
Many times, the data that you want is not already organized into one or a few tables that you can read directly into R. More frequently, you find this data is given in the form of an API. Application Programming Interfaces (APIs) are descriptions of the kind of requests that can be made of a certain piece of software, and descriptions of the kind of answers that are returned. Many sources of data - databases, websites, services - have made all (or part) of their data available via APIs over the internet. Computer programs (“clients”) can make requests of the server, and the server will respond by sending data (or an error message). This client can be many kinds of other programs or websites, including R running from your laptop.
Some basic terminology
Representational State Transfer (REST) - these allow us to query databases using URLs, just like you would construct a URL to view a web page.
Uniform Resource Location (URL) - a string of characters that uses the Hypertext Transfer Protocol (HTTP) and points to a data resource. On the world wide web this is typically a file written in Hypertext Markup Language (HTML). Here, it will return a file containing a subset of a database.
HTTP methods/verbs
GET: fetch an existing resource. The URL contains all the necessary information the server needs to locate and return the resource.
POST: create a new resource. POST requests usually carry a payload that specifies the data for the new resource.
PUT: update an existing resource. The payload may contain the updated data for the resource.
DELETE: delete an existing resource.
The most common method you will use for an API is GET.
How Do GET Requests Work?
A Web Browsing Example
As you might suspect from the example above, surfing the web is basically equivalent to sending a bunch of GET requests to different servers and asking for different files written in HTML.
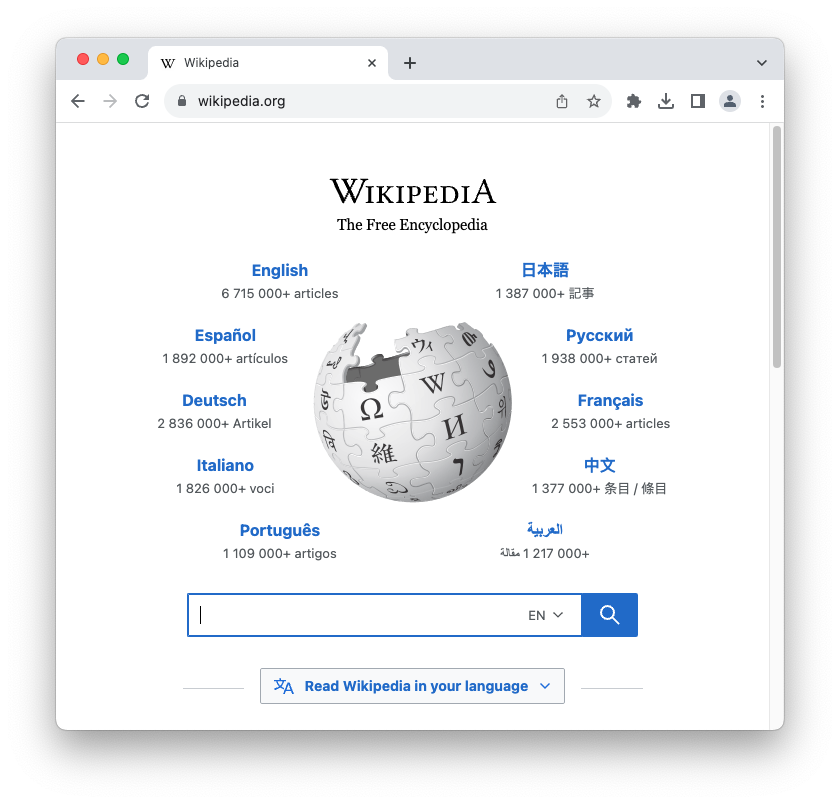
Suppose, for instance, you wanted to look something up on Wikipedia. The first step would be to open your web browser and type in http://www.wikipedia.org. Once you hit return, you would see the page below.
Several different processes occurred, however, between hitting “return” and the page finally being rendered. In order:
The web browser took the entered character string, used the command-line tool “Curl” to write a properly formatted HTTP GET request, and submitted it to the server that hosts the Wikipedia homepage.
After receiving this request, the server sent an HTTP response, from which Curl extracted the HTML code for the page (partially shown below).
No encoding supplied: defaulting to UTF-8.
<!DOCTYPE html>
<html lang="en" class="no-js">
<head>
<meta charset="utf-8">
<title>Wikipedia</title>
<meta name="description" content="Wikipedia is a free online encyclopedia, created and edited by volunteers around the world and hosted by the Wikimedia Foundation.">
<script>
document.documentElement.className = document.documentElement.className.replace( /(^|\s)no-js(\s|$)/, "$1js-enabled$2" );
</script>
<meta name="viewport" content="initial-scale=1,user-scalable=yes">
<link rel="apple-touch-icon" href="/static/apple-touch/wikipedia.png">
<link rel="shortcut icon" href="/static/favicon/wikipedia.ico">
<link rel="license" href="//creativecommons.org/licenses/by-sa/4.0/">
<style>
.sprite{background-image:linear-gradient(transparent,transparent),url(portal/wikipedia.org/assets/img/sprite-8bb90067.svg);background-repeat:no-repeat;display:inline-block;vertical-align:middle}.svg-Commons-logo_sister{background-position:0 0;width:47px;height:47px}.svg-MediaWiki-logo_sister{background-positi
The raw HTML code was parsed and then executed by the web browser, rendering the page as seen in the window.
Web Browsing as a Template for RESTful Database Querying
The process of web browsing described above is a close analogue for the process of database querying via RESTful APIs, with only a few adjustments:
While the Curl tool will still be used to send HTML GET requests to the servers hosting our databases of interest, the character string that we supply to Curl must be constructed so that the resulting request can be interpreted and successfully acted upon by the server. In particular, it is likely that the character string must encode search terms and/or filtering parameters, as well as one or more authentication codes. While the terms are often similar across APIs, most are API-specific.
Unlike with web browsing, the content of the server’s response that is extracted by Curl is unlikely to be HTML code. Rather, it will likely be raw text response that can be parsed into one of a few file formats commonly used for data storage. The usual suspects include .csv, .xml, and .json files.
Whereas the web browser capably parsed and executed the HTML code, one or more facilities in R, Python, or other programming languages will be necessary for parsing the server response and converting it into a format for local storage (e.g., matrices, dataframes, databases, lists, etc.).
Install and play packages
Many common web services and APIs have been “wrapped”, i.e. R functions have been written around them which send your query to the server and format the response.
Why do we want this?
Reproducibility
Ease of access
Much easier to keep track of revisions and updates
Scales to a far larger userbase
API queries
If an R package does not already exist for an API, you can still query it using something such as the httr or httr2 packages.
Web scraping
If the web site does not have an API, you could utilize web scraping to systematically and reproducibly extract data from the source code of website, using either an HTML parser (easy) or regular expression matching (less easy).